CLIP Gets a Data Upgrade: Outperforming SoTA with Improved Data Curation Only
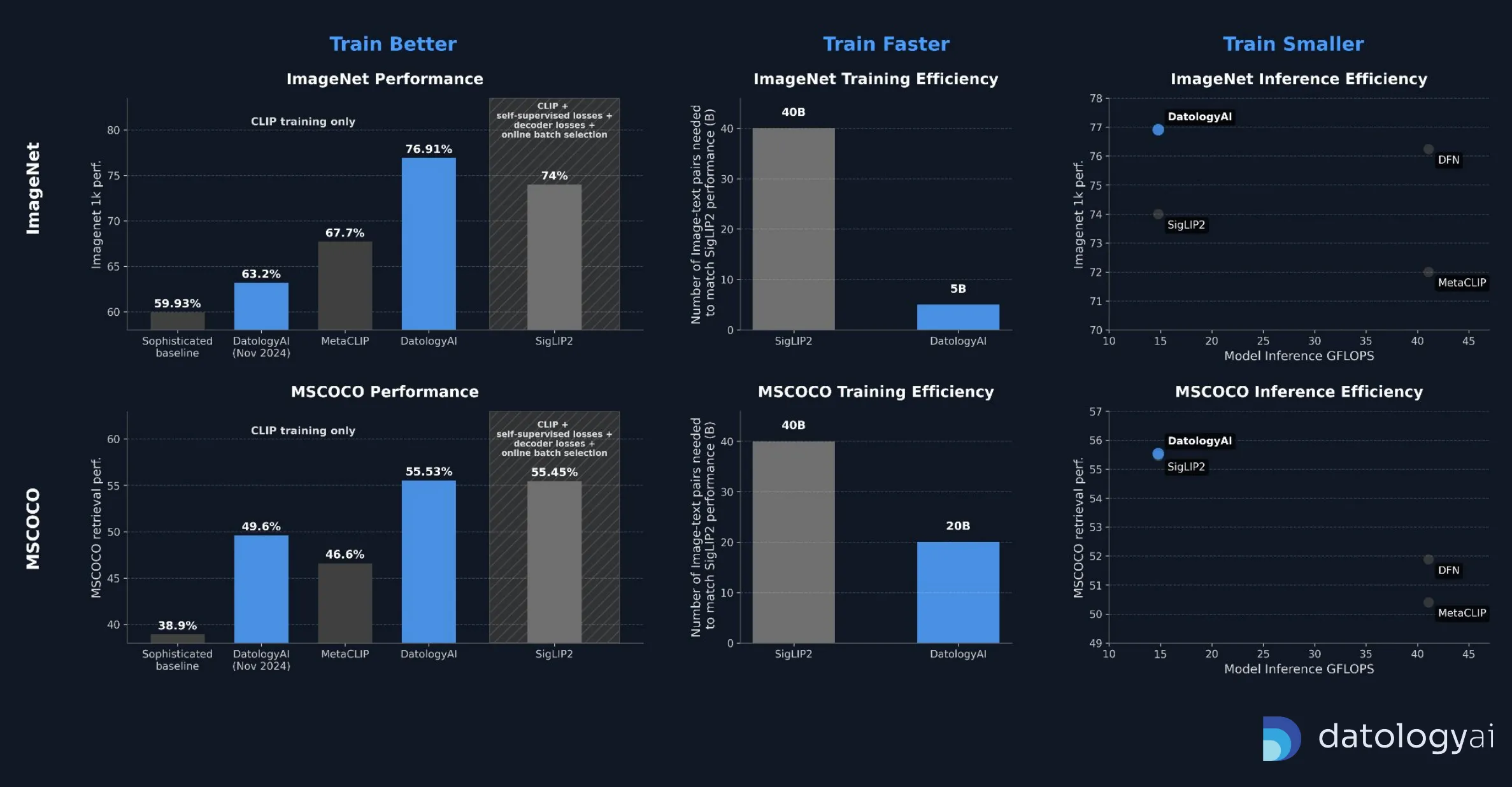
Train Better, Faster, and Smaller with DatologyAI’s Multimodal Data Curation. We present results for CLIP ViT-B/32 models trained on our latest data curation pipelines for classification (top row) and retrieval (bottom row). In each case, we compare DatologyAI to state-of-the-art models, such as SigLIP2, MetaCLIP, and DFN as well as models from our November 2024 blog post. Models trained using our data curation outperform state-of-the-art methods (left panels) and can match the performance of SigLIP2 with only a fraction of the training budget (middle panels). Finally, ViT-B/32 CLIP models trained with DatologyAI’s multimodal data curation pipeline outperform ViT-B/16 models trained with MetaCLIP and DFN curation (right panels), resulting in a 2.7x reduction in inference costs.
Note: This is a standalone post, but it builds on our previous multimodal curation results, where you can find additional scientific context and methodological details.
Introduction
High-quality data curation drives breakthroughs in AI models. In earlier work, our image-text curation pipeline was shown to yield substantial improvements in CLIP model quality, training efficiency, and inference costs. We built on that foundation, advancing both the scientific and engineering aspects of our curation approach to achieve state-of-the-art (SoTA) results across a range of classification and retrieval benchmarks. As with our prior work, we start with the Datacomp CommonPool and all performance gains we report here are solely attributable to improvements in training data — we make no changes to model architecture or training procedures and use the standard CLIP loss throughout. Our results underscore that careful data curation alone can yield SoTA performance, without the need for modifications to model architecture or training paradigms.
-
Our classification optimized CLIP models obtain SoTA performance across a range of model variations, from ViT-B/32 to ViT-L/14. Models trained on DatologyAI curated data outperform SigLIP2, MetaCLIP, and DFN-trained models across zero-shot ImageNet 1k and ImageNet v2 classification tasks and yield training efficiency improvements of up to 8x.
-
Our retrieval optimized CLIP models have also improved significantly since our November 2024 blog post, achieving SoTA performance for ViT-B/32 models on MSCOCO together with a 2x training efficiency gain compared to SigLIP2.
Our focus has been on improving data curation so our results here all rely on standard CLIP models and workflows. As such, we emphasize that the benefits of data curation are complementary to gains achieved through advances in model architectures, optimization algorithms, and objective functions. As part of this blog post, we’re also releasing ViT-B/32 models trained with our SoTA DatologyAI data curations — these models are available here.
Results
Building on our earlier blog post, Figure 1 presents competitive results against leading CLIP models (e.g., SigLIP2, MetaCLIP, DFN) across a range of models from ViT-B/32 to ViT-L/14. Our latest data curation pipelines enable models that not only match or surpass state-of-the-art performance (train better) but do so with significantly less compute (train faster). Additionally, we show that smaller, more efficient models trained with our pipeline can rival or exceed the performance of much larger models (train smaller).
Train better: Outperforming SoTA with Data Curation Alone
Classification
The substantial improvements in the DatologyAI curation pipeline are particularly pronounced over the ViT-B family of models, where we demonstrate SoTA performance across popular classification benchmarks such as ImageNet 1k and ImageNet v2. Concretely, the performance of our ViT-B/32 models yields greater than 2.5% absolute improvement over the recently released SigLIP2 family of models (76.91% compared to 74.0% as reported in SigLIP2). This is particularly impressive given that DatologyAI models utilize a significantly simpler training paradigm, which does not introduce any new training objectives or model training tricks, and are trained for a fraction of the compute budget (13B image-text pairs compared to 40B for SigLIP2; see Figure 2 below). Finally, we demonstrate that the benefits of our data curation also extend to larger, more expressive models and obtain SoTA performance for ViT-L/14 models with a 1.4% absolute improvement on ImageNet 1k compared to the best publicly reported model (82.8% compared to 81.4% reported by DFN).
When benchmarking against other models which focus primarily on data interventions, such as MetaCLIP and DFN, we also observe large performance deltas: at the ViT-B/32 scale we observe a ~9% absolute improvement in ImageNet 1k and ImageNet v2 performance compared to MetaCLIP. We also see improvements at the ViT-B/16 scale where DatologyAI models observe ~4% absolute improvements over DFN models.
Retrieval
The retrieval performance of CLIP models trained using our retrieval optimized data curation pipelines is also competitive, with DatologyAI models obtaining greater than 5% absolute improvements over both MetaCLIP and DFN models on Flickr and MSCOCO benchmarks at the ViT-B scale and a greater than 3% absolute improvement at the ViT-L/14 scale. For example Figure 1 shows that at the ViT-B/16 scale, DatologyAI models obtain a 5.4% absolute improvement over MetaCLIP on Flickr (83.5% compared to 78.1%) and a 7.8% absolute improvement on MSCOCO (58.2% compared to 50.4%).
When compared to SigLIP2, DatologyAI models are able to slightly exceed the performance on MSCOCO at the ViT-B/32 scale despite being trained for a fraction of the compute budget and using only vanilla CLIP objectives. For larger model variations, DatologyAI models lag behind SigLIP2. We attribute these differences to the impressive (and complex) training paradigm of SigLIP2, which incorporates a host of auxiliary loss functions ranging from masked prediction and self-distillation to online batch selection and distillation as well as to the fact that our retrieval optimized models were only trained up to 20B image-text pairs, whereas SigLIP2 models where trained for 40B. It is important to emphasize that improvements in data curation are likely to be complementary to the optimization and objective advancements achieved in SigLIP2.
Figure 1: We report the performance of CLIP models across a range of model sizes (quantified via FLOPS). DatologyAI achieves SoTA performance across a range of classification and retrieval tasks. DatologyAI models achieve SoTA performance for classification tasks such as ImageNet 1k and ImageNet v2. For retrieval tasks, DatologyAI exceeds the performance of SigLIP2 on MSCOCO for ViT-B/32 models (note: this comes with a 2x training efficiency improvement as shown in Figure 3). For many evaluations, ViT-B/16 DatologyAI models are able to match the performance of MetaCLIP and DFN ViT-L/14 models, resulting in a 2.7x reduction in inference costs.
Train Faster: Up to 8x Training Efficiency Gains via Curation
Classification
In Figure 2 we observe large training efficiency improvements, with DatologyAI ViT-B/32 models able to achieve equivalent ImageNet1k zero-shot performance to SigLIP2 with an 87.5% reduction in compute (5B image-text pairs training budget for us compared to 40B for SigLIP2). Similarly, we are able to match MetaCLIP performance despite using 92% less compute (1B training budget compared to 12.8B for MetaCLIP).
Figure 2: DatologyAI data curation drives large training efficiency gains. We visualize classification performance of ViT-B/32 CLIP models as a function of the number of image-text pairs seen during training. DatologyAI data curation yields over 80% reduction in training costs compared to SigLIP2 and MetaCLIP respectively.
Retrieval
Similarly, Figure 3 shows training efficiency improvements for retrieval. When compared to SigLIP2, our ViT-B/32 models are able to match performance on MSCOCO with half the number of image-text pairs (40B for SigLIP2 compared to 20B for DatologyAI). When compared to MetaCLIP, models trained with DatologyAI curated data obtain a 92% reduction in training compute (1B training budget compared to 12.8B for MetaCLIP). While DatologyAI models trained with up to 20B image-text pairs (half the total compute of SigLIP2) do not meet the Flickr performance of SigLIP2, we do observe significant training efficiency improvements compared to MetaCLIP.
Overall, models trained with DatologyAI curated data yield significant training efficiency gains. These efficiency gains are most pronounced when compared to other models that focus exclusively on data curation, such as MetaCLIP. For both classification and retrieval evaluations, models trained with DatologyAI are able to match the performance of MetaCLIP using less than one tenth of the training data (1B image-text pairs compared to 12.8B for MetaCLIP).
Figure 3: DatologyAI data curation also yields significant training efficiency wins across retrieval tasks. We visualize retrieval performance for ViT-B/32 models trained over varying numbers of image-text pairs.
Train Smaller: Improved Data Curation Unlocks Inference Compute Savings
Classification
Across a range of popular classification benchmarks, we find that DatologyAI models obtain an order of magnitude improvement in inference costs. Figure 1 visualizes how DatologyAI ViT-B/32 models outperform MetaCLIP and DFN ViT-B/16 models across ImageNet 1k and ImageNet v2, resulting in a greater than 60% reduction in inference costs. Moreover, DatologyAI ViT-B/16 models also outperform MetaCLIP ViT-L/14 models, implying a greater than 70% reduction in inference cost.
Retrieval
The inference time efficiency gains also translate to retrieval benchmarks. Figure 1 visualizes DatologyAI ViT-B/32 exceeding the retrieval performance of ViT-B/16 MetaCLIP and DFN models across Flickr and MSCOCO — corresponding to a 60% reduction in inference cost. We also see similar trends with our ViT-B/16 models, which match or exceed the performance of MetaCLIP and DFN trained ViT-L/14 models.
Key Scientific Improvements
The DatologyAI data curation pipelines consists of a suite of distinct algorithm families. Throughout this work, we have built upon the initial version of multimodal data curation, described in depth in our prior blog post. Following from the prior blog post, we continue to develop two separate data curation pipelines, one optimized for classification and a second tailored for retrieval.
Our model quality gains are primarily driven by a series of scientific and engineering advances which improve the overall quality and scalability of our data curation pipelines:
-
Improved target distribution matching: Web-scale datasets are inherently vast and heterogeneous, with significant variation in both quality and relevance across subsets. Consequently, modern data curation workflows often prioritize the identification of high-quality, domain-relevant subsets within these large corpora (Gadre et al, 2023, Wang et al, 2024). In our work, we found that identifying high-quality, relevant subsets led to substantial performance gains in CLIP training. However, the multimodal nature of CLIP introduces a challenge: should quality and relevance be defined over the image features, text features, or both? Our experiments suggest that the optimal strategy is task-dependent. For example, retrieval tasks benefited more from aligning distributions along text representations, whereas classification tasks showed greater improvements when alignment was based on image features.
-
Improved Synthetic Data: Leveraging synthetic data effectively at scale is not a plug-and-play solution. Small distributional mismatches can degrade performance, and mode collapse can severely limit model diversity and capability. While our original blog post we had seen large improvements from synthetic data for retrieval tasks, these benefits did not extend to classification tasks. In this work, we generalized our synthetic data pipeline to also benefit classification evals, identifying various properties of synthetically generated image captions which negatively impacted the performance on classification tasks. As a concrete example, synthetically generated image captions tended to be significantly longer than natural captions — this induces a large distribution mismatch with (typically short) templates used during classification evaluation (Radford et al., 2021). These insights helped us improve our synthetic data generation pipelines for classification tasks.
-
Predictive Metrics for Curation Quality: A significant challenge when iterating on data curation pipelines is the need to train and evaluate models in order to ensure that data curation interventions are in fact yielding significant improvements. Indeed, practitioners may need to run many thousands of slow and expensive experiments to verify complex data curation pipelines and carefully select associated hyper-parameters. To tackle this challenge, we developed predictive metrics to approximate the effect of data curation interventions without needing to train and evaluate models. These cheap-to-compute metrics enabled rapid iteration and informed the selection of numerous hyper-parameters within our data curation algorithms. They also helped to identify beneficial curation steps that may not have been intuitively incorporated into our CLIP data pipelines. In total, we conducted over one thousand distinct experiments and ablations prior to finalizing the pipeline.
For further details about the DatologyAI multimodal data curation pipeline, please see our in-depth blog post here.
Experimental details
Our objective is to highlight the large-scale improvements which can be obtained exclusively by improving data curation. As such, we did not modify architecture, optimizer, objective functions, etc, and focused entirely on standard CLIP models and training procedures.
Our model evaluation follows the same setup as described in our prior blog post. We evaluate models across 27 tasks which are divided into 24 classification tasks, which require models to correctly identify a category label for an image, and 3 retrieval tasks, which require a model to identify the most relevant image or text for a given query. Throughout this blog post we have focused primarily on ImageNet 1k, ImageNet v2, MSCOCO and Flickr as these are evaluations which are frequently reported — we provide a full breakdown of our performance in the Appendix.
Our primary results focused on training CLIP ViT-B/32 models as described in Radford et al 2021. We relied on the open source OpenCLIP training repository (Cherti et al 2024, release 2.24.0) and used default architectures and hyper-parameters. To complement the results of our ViT-B/32 models, we also report performance across ViT-B/16 and ViT-L/14 models. Following our prior blog post, we continue to develop two separate data curation recipes which are tailored for classification and retrieval tasks, respectively. This choice is motivated by the various distinct applications of CLIP models which are frequently deployed independently.
Data
All experiments presented in this blog post leverage the DataComp multimodal benchmark dataset (Gadre et al., 2023). While our original blog post focused on the DataComp Large filtering track, in this work we further extended our data pool-size to the Extra-Large filtering track. This expands our pool-size by a factor of 10, going from 1B in our original blog post to 10B image-text pairs. We note that the while the Extra-Large filtering track indexes 12.8B image-text pairs, we were only able to obtain 10B pairs, which we primarily attribute to dead links. Our curation refined this data down to approximately 1B high quality image-text pairs.
Summary
Our previous blog post introduced a sophisticated data curation pipeline yielding improved CLIP model quality, faster training and reduced inference costs. We’ve built on these results, advancing our curation in several key areas, ranging from improved target distribution matching and synthetic data workflows to more robust engineering workflows. As a result, CLIP models trained with DatologyAI curated data achieve SoTA performance across a range of evaluations at a fraction of the compute cost.
Our journey is just beginning. We’re actively improving our multimodal data curation pipeline and associated research. Our nexts steps will be to focus on data curation vision-language models (VLMs).
As we continue to innovate, we invite collaboration and feedback from the broader community. If you’re an enterprise AI company seeking faster, better, or more cost-effective training solutions for multimodal and text models, we’d love to connect. Get in touch here and join us in shaping the future of AI data curation.
If you are interested in pushing the boundaries of what is possible with data curation, we are actively recruiting across a range of roles. We are particularly excited about researchers and engineers who have experience doing data research, building research tooling, translating science into products, and building scalable data products.

Contributors
Core Contributors
Ricardo Pio Monti • Haoli Yin • Amro Abbas • Alvin Deng • Josh Wills
Contributors
Cody Blakeney • Paul Burstein • Aldo Carranza • Parth Doshi • Pratyush Maini • Kaleigh Mentzer • Luke Merrick • Fan Pan • David Schwab • Jack Urbanek • Zhengping Wang
Leadership and Advising
Matthew Leavitt • Bogdan Gaza • Ari Morcos
For attribution in academic contexts, please cite this work as
Monti et al., “CLIP Gets a Data Upgrade: Outperforming SoTA with Improved Data Curation Only”, 2025.
@techreport{monti_clip_upgrade_2025,
title = {{CLIP} {Gets} a {Data} {Upgrade}: {Outperforming} {SoTA} with {Improved} {Data} {Curation} {Only}},
url = {https://blog.datologyai.com/multimodal-plus-blogpost},
institution = {DatologyAI},
author = {DatologyAI Team},
month = jun,
year = {2025},
}Appendix
A1. The Big Plot
Figure A.1: Comprehensive results plot (aka The Big Plot). Here, we enable viewing the results for all evaluations, each of which you can control using the dropdown menus at the top of the plot. Each point represents the final accuracy of a model trained with a given number of training samples, i.e., each point corresponds to a distinct model. For MetaCLIP, we took results reported in Xu et al., Table 9. For SigLIP2, we report results from Tschannen et al., Table 1 and our own evaluations the remaining evaluations. We calculated FLOPs using OpenCLIP measurements, and we skipped SigLIP2’s FLOPs as these were not available. Evaluations marked with a * are those we defined as noisy. We skipped the SugarCrepe benchmarks for MetaCLIP, as the authors did not report them in the paper.
A2. Related work and baselines
Contrastive Image-Language Pretraining (CLIP) models, first introduced by Radford et al., 2021, has established themselves as the industry-standard approach to learn semantically meaningful visual representations grounded in natural language. The success of such models is evidenced by the fact that they are often combined with LLMs to yield performant vision language models.
In recent years, there has been a dramatic improvement in the quality of CLIP models. These advances can be broadly divided into two complementary camps: improved overall training methodology and better understanding and curation of the training data. In terms of improved training methodology, notable contributions include the proposal of novel objective functions such as SigLIP (Zhai et al, 2023) and SigLIP2 (Tschannen et al., 2025) and methodology focused on active batch curation such as JEST (Evans et al, 2024) and ACID (Udandarao et al, 2024). In this blog post we compare extensively to SigLIP2 which combines many independently developed techniques into a unified, and highly performant, recipe. Some of the key innovations which are incorporated in SigLIP2 include self-supervised losses such as SILC (Naeem et al, 2023) and TIPS (Maninis et al, 2025), caption-based localization-aware pretraining in the form of LocCa (Wan et al, 2024) and active batch selection (employed only for smaller models).
Of greater interest to us are advances driven exclusively via improved data curation. For example, Data Filtering Networks (Fang et al., 2024) train CLIP models to filter large-scale uncurated datasets, achieving significant improvements in model performance with a fraction of the total data. MetaCLIP (Xu et al., 2024) finds that “the main ingredient to the success of CLIP is its data and not the model or the pre-training objective”; they focus exclusively on data curation, finding that metadata-based curation and balancing are needed to train effective CLIP models.