
NOTE: If you prefer a PDF, the ArXiv version of this post can be found here.
Executive Summary
In this post we present BeyondWeb, the synthetic data component of our pretraining data curation pipeline. BeyondWeb is a synthetic data generation framework that leverages targeted document rephrasing to yield diverse, relevant, and information-dense synthetic pretraining data. Here we show that BeyondWeb substantially outperforms existing state-of-the-art public pretraining datasets and share some of the lessons we learned along the way about why it’s so hard to generate high-quality synthetic pretraining data. To learn more about our full data curation pipeline beyond BeyondWeb, see this blog post.
Motivation
Recent advances in LLM pretraining have shown that simply scaling data quantity eventually leads to diminishing returns, hitting a data wall, beyond which data of high information-density is prohibitively scarce. Synthetic data has emerged as a powerful complement to scarce, high-quality web text. The success of synthetic data methods has led research organizations to pour substantial compute resources into creating ever larger corpora of synthetic data cite, a trend most recently highlighted as a key innovation in GPT-5’s development cite. While we know that synthetic pretraining data can work, we still lack a comprehensive scientific understanding of the factors that determine when and how synthetic pretraining data works. Understanding these factors is ultimately what allowed us to develop BeyondWeb.
BeyondWeb: A Scalable Framework for State-of-the-Art Synthetic Pretraining Data
We trained models from 1B to 8B parameters on datasets up to 1 trillion tokens, and BeyondWeb consistently outperformed even the strongest public synthetic pretraining datasets, allowing us to:
-
Train better. At the 8B scale, BeyondWeb exceeds HuggingFace’s Cosmopedia and NVIDIA’s Nemotron-CC high-quality synthetic subset by 5.1 percentage points (pp) and 2.6pp, respectively, when averaged across a suite of 14 benchmark evaluations.
-
Train faster. BeyondWeb delivers up to 7.7× faster training than open web data and 2.7× faster than Nemotron Synthetic.
-
Train Smaller. A 3B model trained for 180B tokens on BeyondWeb outperforms an 8B model trained for the same token budget on Cosmopedia.
The Challenges and Lessons of Generating Foundation-Scale Synthetic Pretraining Data
We also share seven challenges and lessons from our research developing BeyondWeb.
-
Synthetic data is not just knowledge distillation. We find that a simple summarization-based rephrasing approach is able to nearly match the performance of the much more expensive approach of Cosmopedia. However, BeyondWeb outperforms summarization-based approaches by a clear margin, showing that substantial gains are possible beyond basic distillation, and underscoring the importance of intentional synthetic data approaches (§4.2).
-
Synthetic data approaches must be thoughtful to improve over real data. Trying to increase the size of a dataset by simply extending web documents using LLMs provides limited improvement over just repeating the web data and may not be able to breach the data wall. Synthetic data generation must be intentionally designed (§4.3).
-
Using higher quality input data helps, but only to a point. Given limited high-quality data, it is more beneficial to use it as seed data for synthetic rephrasing rather than using low-quality data, despite the possible drawback of repeating knowledge from the high-quality sources. Nevertheless, high-quality input data alone is insufficient for generating the highest quality synthetic data (§4.4).
-
Style matching is useful but not sufficient. Conversational content is a small fraction of web data (<5%), yet chat and in-context learning are the primary inference use cases of LLMs. Upsampling natural conversational data improves downstream task performance, though these improvements are modest and show diminishing returns with the proportion of conversational data (§4.5).
-
Diversity enables scalable learning. While standard synthetic data generation methods provide benefits early in training, their lack of stylistic diversity leads to diminishing returns. Multi-faceted approaches continue providing valuable learning signals throughout training, whereas single-strategy methods saturate (§4.6).
-
Most rephrasers are fine. Synthetic data benefits are largely robust across rephraser model families. Additionally, generator model quality is not predictive of synthetic data quality. Selecting a good rephrasing model may be straightforward as most work well, but selecting the best rephrasing model is not (§4.7).
-
Small LLMs can be effective rephrasers. The quality of synthetic data increases when increasing rephraser size from 1B to 3B, then starts to saturate at 8B. The simplicity of rephrasing makes generator size less critical, enabling highly scalable synthetic pretraining data generation even with small models (§4.8).
Takeaway
We show that generating high-quality synthetic pretraining data is difficult, ensuring its effectiveness for larger models and training budgets is even harder, and risks being extremely costly to generate. Furthermore, there is no silver bullet for synthetic data, strong outcomes require jointly optimizing many variables. However, all of these challenges and risks are surmountable with thoughtful, scientifically rigorous source rephrasing, as evidenced by BeyondWeb substantially outperforming other public synthetic pretraining data offerings.
Are you a deep learning fanatic, data engineer, or otherwise data-obsessed person who wants to push the bounds of what’s possible with data curation? Check out our jobs page!
Is your company interested in training models faster, better, or smaller? Get in touch!
Follow us on twitter for insights (and memes) about data!
1. Introduction
1. Introduction
Until 2024, breakthroughs in language modeling followed a predictable recipe: train ever-larger models on exponentially larger internet-scraped datasets. However, as the scale of data collection ballooned into the trillions of tokens, the field began to encounter a data wall, beyond which data of high information-density becomes prohibitively scarce. The returns on collecting more internet data rapidly diminished, pushing researchers toward exploring alternative paradigms.
Synthetic data has emerged as a powerful complement to scarce, high-quality web text. Initial evidence from Tiny Stories cite showed that targeted prompting of large language models can generate data suitable to train small language models from scratch. Follow-up work, most notably Microsoft’s Phi family cite and the open-source Cosmopedia corpus cite, demonstrated that sub-2B models jointly trained on synthetic and raw data can outperform much larger baselines. We refer to this practice of using large models to generate training data de novo as the generator-driven approach.
Generator-driven approaches, while powerful, are ultimately limited by the cost and idiosyncrasies of the large generator models they rely on, such as GPT-4 cite. To address these limitations, the Web Rephrase Augmented Pre-training (WRAP) paradigm cite and its refinement in Nemotron-CC cite developed what we refer to as the source rephrasing approach. In these works, rather than prompting a large LLM to create knowledge de novo, small LLMs are used to rephrase existing web data into higher-quality, task-aligned formats (e.g., Q&A pairs, instructional passages). This approach achieves superior coverage and diversity at lower compute costs, establishing synthetic rephrasing as a practical solution for pretraining-scale data generation.
The success of synthetic data methods has led research organizations to pour substantial compute resources into creating ever larger corpora of rephrased synthetic data cite. Most recently, synthetic data was specifically highlighted as a key innovation in GPT-5’s development cite. While we know that synthetic pretraining data can work, we still lack a comprehensive scientific understanding of the factors that determine when and how synthetic pretraining data works.
Our work systematically addresses these questions and highlights the challenges of scalably generating high-quality pretraining data by conducting experiments across model scales up to 8B parameters. Specifically, we address the following:
How Does Synthetic Data Provide its Benefits?
- First, we assess whether the model quality improvements imparted by the generator-driven paradigm can be explained as distillation of a teacher model’s knowledge into higher per-token information density data. We find that simple summarization prompts in the source-rephrasing paradigm can match the performance of generator-driven approaches such as Cosmopedia (§4.2).
- Next, we ask whether synthetic data can actually breach the data wall. We show that in a data-constrained setting, naive approaches such as simple continuations (of existing web data) provide limited accuracy improvements over just repeating data. However, thoughtfully-created data that fills in the distributional gaps of the web data has much larger benefits (§4.3).
What and How to Rephrase?
- First, data quality matters: rephrasing high-quality data provides benefits over using lower-quality sources, but high-quality input data alone is not enough to yield the highest quality synthetic data (§4.4).
- Second, distributional style matching is important. Web data contains only 2.7% conversational content, despite chat being a major inference use case. Style matching improves performance in downstream tasks, but the benefits saturate quickly with the proportion of conversational data, indicating that it is not a sufficient solution (§4.5).
- Third, diversity in generation strategies is critical to leverage continued benefits from synthetic data when scaling to large training budgets of trillions of tokens (§4.6).
Who Should Rephrase?
- Synthetic data benefits are largely consistent across different rephraser families, and rephraser quality does not predict synthetic data quality, indicating that rephrasing is a generic capability and rephraser model efficacy is difficult to predict (§4.7).
- We observe diminishing returns when increasing rephraser size beyond 3B parameters, with 8B LLMs achieving only marginal gains over 3B. This validates that (given the right recipe) effective synthetic data generation doesn’t necessarily require massive computational resources (§4.8).
Motivated by these insights, we introduce BeyondWeb, a synthetic pretraining data generation paradigm that leverages targeted document rephrasing to yield diverse, relevant, and information-dense synthetic data. On 8B models trained for 180B tokens, we outperform RedPajama cite and the high-quality synthetic subset of Nemotron-CC (Nemotron-Synth) by +7.1pp and +2.6pp, respectively, while achieving training speedups of 7.7× and 2.7×. Furthermore, 3B model trained on BeyondWeb surpasses the performance of strong 8B baselines such as Cosmopedia. This establishes a new pareto frontier for the accuracy-efficiency trade-off in LLM pretraining.
Our results also indicate a promising scaling trend: the benefits of our approach show consistent gains across model sizes, achieving (+3.1pp, +2.0pp, +2.6pp) over Nemotron-Synth at 1B, 3B, 8B parameters respectively.
We note that BeyondWeb is one part of our full curation platform, which was used to curate the 7T token pretraining dataset for ArceeAI’s AFM4.5B model cite—and combining BeyondWeb with our full curation platform obtains even better results. The strength of AFM4.5B demonstrates the efficacy of BeyondWeb not just in the controlled experimental settings presented here, but also as part of an end-to-end curation pipeline for generating foundation-scale pretraining datasets for production models.
Overall, our work demonstrates that generating high quality synthetic data is not a trivial task, and that there is no singular silver bullet solution for obtaining the highest quality synthetic data. Naive approaches to synthetic data generation can provide little benefit or even some detriment, while also incurring substantial computational cost for generation. In contrast, the right synthetic generation approach can yield exceptional model quality improvements, as demonstrated by our BeyondWeb results. Getting synthetic data right requires careful consideration of numerous factors, including data selection strategies, generation methodologies, diversity preservation, and quality control, making it a challenging endeavor that demands rigorous science and practical expertise.
2. A Tale of Two Approaches for Synthetic Pretraining Data Generation
2. A Tale of Two Approaches for Synthetic Pretraining Data Generation
The Generator-Driven Paradigm: Creating Knowledge from Models de Novo
The generator-driven approach to synthetic data uses large-scale models to generate training data from scratch, encapsulating the knowledge embedded within these models. By generating data from a pretrained model, researchers have been able to substantially improve the performance of the next generation of models. Notably, the seminal work on Tiny Stories cite demonstrated that high-quality, carefully prompted synthetic data, such as simplified narratives crafted by GPT-4, could effectively train small language models from scratch. This result defied the prevailing trend of scaling models and web data, sparking a paradigm shift and paving the way for increased use of synthetic data for pretraining small, performant models.
Soon after, the Phi model family cite advanced the generator-driven approach by training small (<2B parameter) models jointly on synthetic data and raw web data, and were able to outperform models up to 10× larger using a fraction of the training compute. Cosmopedia cite furthered this direction by introducing a large-scale, open-source synthetic dataset, generated by leveraging open-source LLMs and prompting it with a diverse set of curated seed topics. However, this paradigm, which relies on using a powerful existing model as a knowledge bank to generate synthetic data, is constrained by the high computational cost of accessing state-of-the-art generators like GPT-4, making it inaccessible to many researchers. Furthermore, these approaches do not scale well and are susceptible to model collapse cite, as they inherit the knowledge and biases of the generator, potentially resulting in limited diversity, coverage gaps, and hallucinated content cite.
The Source Rephrasing Paradigm: Enhancing Existing Knowledge
Motivated by the shortcomings of the generator-driven approach, cite recently proposed an alternative synthetic generation methodology: Web Rephrase Augmented Pre-training (WRAP). WRAP leverages existing web documents and employs smaller models to rephrase this content into higher-quality, structured and/or targeted formats. Conditioning on existing data significantly reduces dependence on expensive large models while enriching the training corpus with natural, diverse, and topical language. cite were able to speed up pretraining by more than 3× through the use of strategic rephrasing. Of note, cite concurrently worked on rephrasing articles during pretraining on a toy task of author biographies, and showed such rewriting enhanced model performance. We refer to this collection of methodologies as the source rephrasing paradigm.
The source rephrasing approach has gained considerable traction in industry. Projects such as Nvidia’s Nemotron-CC cite, StabilityAI’s multilingual augmentation efforts cite, and Microsoft’s Phi-4 cite have all built on this paradigm, emphasizing the value of augmenting real-world internet data. This highlights a critical ideological shift toward data-driven rather than model-driven synthetic data generation. This approach effectively combines the advantages of broad, naturally occurring knowledge from the internet with controlled style and format enhancements. In 2025, rephrasing has become the dominant paradigm with state-of-the-art LLMs like Kimi K2 cite, Qwen-2.5 cite, Grok cite, and GPT-5 cite reporting substantial use of and/or meaningful gains from source rephrasing.
Synthetic Data Beyond Pretraining
The utility of synthetic data extends beyond pretraining and into other phases of model development, including fine-tuning and evaluation. Synthetic data can play a pivotal role in addressing specific task-oriented training objectives, aligning model behavior, reducing toxicity, and improving generalization on targeted downstream tasks. Techniques such as instruction-tuning, Chain-of-Thought prompting, and data backtracing emphasize synthetic data’s potential beyond pretraining by directly influencing downstream capabilities, such as reasoning cite, alignment cite, and reducing model hallucinations cite. However, the relative lack of synthetic data research for pretraining compared to post-training and the potential magnitude of impact from successful pretraining improvements motivated us to focus exclusively on synthetic data for pretraining in this work.
3. Introducing BeyondWeb
3. Introducing BeyondWeb
We introduce BeyondWeb, a synthetic data approach that leverages grounding and diversity to substantially improve language model pretraining efficiency. It combines the broad coverage of web-scale corpora with strategically-generated content that fills critical gaps, particularly in underrepresented styles, formats, and topics. BeyondWeb employs diverse generation strategies, including format transformation (e.g. converting web content into question–answer pairs), style modification (e.g. enhancing pedagogical tone), and content restructuring to improve information density and accessibility. This enables the creation of models better aligned with real-world language use and downstream task demands.
Datasets. We compare BeyondWeb against state-of-the-art public synthetic pretraining datasets and methodologies, as well as a non-synthetic open web dataset, RedPajama (RPJ) cite. We chose RPJ because it is a well-established baseline that has minimal curation applied to it, allowing us to robustly assess the effects synthetic data. For comparisons with other synthetic datasets, we adopt a mixed curation strategy: 60% of the training tokens are sourced randomly from RPJ, while 40% come from synthetic data. We evaluate against three synthetic baselines:
- Cosmopedia cite contains over 39 million textbooks, blog posts, and stories generated by Mixtral-8×7B-Instruct-v0.1, using web-derived prompts covering a predefined set of topics. We use the latest version, Cosmopedia-v2, which contains approximately 27 billion tokens. When more tokens are needed for our experiments, we repeat the dataset to compensate. While repetition is not ideal because it potentially reduces the effective per-token quality of the dataset, we consider this a general limitation of the generator-driven paradigm that stems from the cost and difficulty of prompting and generation.
- WRAP cite rephrases web content into various formats, with question-answering being the most performant style. For our comparison, we use the RedPajama dataset as the source corpus for rephrasing, and the Llama-3.1-8b-Instruct LLM for rephrasing.
- Nemotron-Synth cite is the high-quality subset of synthetic data in Nemotron-CC. The data was generated by applying diverse rephrasing prompts to high-quality, classifier-selected inputs. We chose the subset of Nemotron-CC synthetic data derived from high-quality input data, which we refer to as Nemotron-Synth, instead of the full Nemotron-CC synthetic data because Nemotron-Synth is an extremely competitive baseline and sufficiently large for our long-horizon experiments. Nemotron-Synth contains 1.5 trillion tokens, so we randomly sample a subset while maintaining the original proportions across different data subsets.
We apply our BeyondWeb approach to a high-quality subset of DCLM cite selected using the methods described in cite.
Synthetic Generation Infrastructure. Generating foundation-scale synthetic pretraining data presents a formidable engineering challenge. We addressed this by building a massively scalable data curation pipeline that collects billions of high-quality documents suitable for rephrasing (as detailed in cite) and then efficiently performs large-scale parallelizable synthetic rephrasing over the resulting trillions of tokens. Furthermore, because our curation platform is not only central to our internal research but also serves as our product, it was designed to be deployable across heterogeneous customer environments. Our initial setup used Slurm on an AWS Hyperpod cluster of H100s, but this system was rigid, slow to iterate on, had deployment constraints, and made it difficult to track experiment choices. This motivated us to move to a solution using Ray and vLLM on Kubernetes. The new setup supports heterogeneous clusters and various GPU types, scales efficiently on Kubernetes, and integrates seamlessly into our existing Ray and Spark curation pipeline. In addition to facilitating deployment and reducing cost and complexity, this also enables us better end-to-end experiment tracking. This infrastructure shift has transformed our synthetic generation system into a flexible, scalable, and production-ready platform that simultaneously accelerates research, streamlines deployment, and powers customer-facing workloads. We look forward to detailing our synthetic data generation infrastructure in a follow-up release.
Training setup. We train three sizes of LLMs: a 1B parameter model trained on 1 trillion tokens, a 3B model trained on 180 billion tokens, and an 8B model trained on 180 billion tokens. We use LLaMA-3.2 architecture cite for the 1B and 3B models, and LLaMA-3.1 architecture for the 8B model. Additional training details can be found in Appendix A of paper. We did not extensively tune hyperparameters other than an early search on the baseline RPJ data, as our goal was to improve model performance with data interventions alone.
Evaluation setup. We evaluated the models on 14 benchmark tasks (enumerated in Appendix B of paper) using both 0-shot and 5-shot prompting and report average accuracy across all settings and tasks. Multiple-choice questions are assessed using a relative scoring method, as described in Hugging Face’s analysis of the OpenLLM leaderboard and referred to as “cloze form” (CF) in cite. This approach compares the probabilities assigned by the model, restricted to the set of valid answer choices.
Performance improvements across scales. BeyondWeb demonstrates consistent improvements across all evaluated model sizes, as shown below. At 1B parameters, we achieve 57.4% average accuracy (+6.7pp over RPJ), establishing a strong foundation. The performance gains become more pronounced as scale increases: at 3B parameters, we reach 60.8% accuracy (+7.3pp over RPJ), and at 8B parameters, accuracy rises to 63.7% (+7.1pp over RPJ). BeyondWeb also consistently outperforms Nemotron-Synth, our strongest synthetic pretraining data baseline, at all scales (+3.1pp, +2.0pp, +2.6pp at 1B, 3B, and 8B, respectively). These results demonstrate that our synthetic data approach remains effective across scales and continues to offer substantial benefits in larger models.
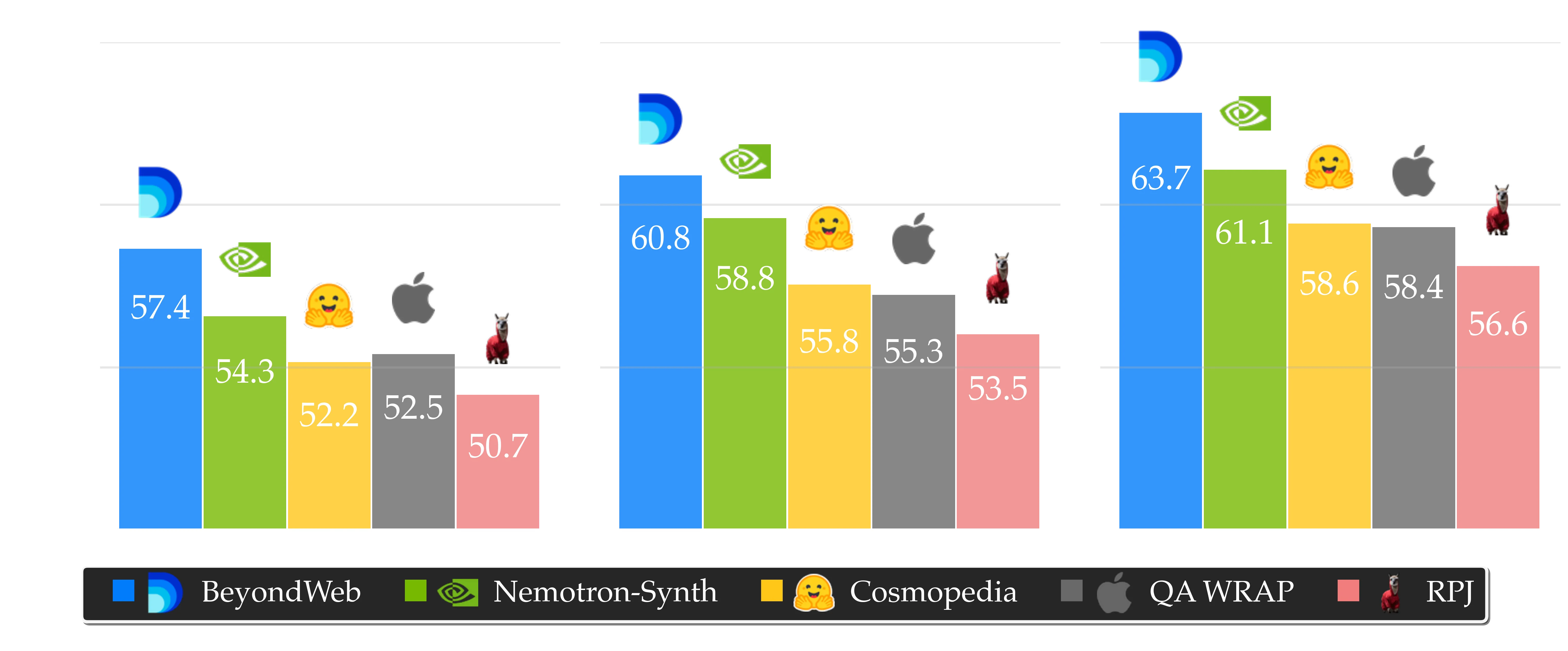
Performance comparison showing BeyondWeb's significant advantages over state-of-the-art baselines across three model scales. Average Accuracy (%) is computed as the mean score across 14 standard benchmarks, averaged over both 0-shot and 5-shot settings.
Train Models 7.7× faster. BeyondWeb enables substantial computational savings during pretraining, as shown in Figure below. For the 8B model, BeyondWeb matches or exceeds RedPajama’s 180B-token performance in just 23.2B tokens (7.7× speedup) and Nemotron-Synth’s 180B-token performance in only 66.2B tokens (2.7× speedup). Faster convergence directly reduces training cost, energy consumption, and iteration time, affording more experiments within a fixed compute budget. This efficiency is valuable not only for large industry labs aiming to optimize costs but also for relatively smaller organizations constrained by infrastructure, thereby helping to democratize access to high-performance LLMs.
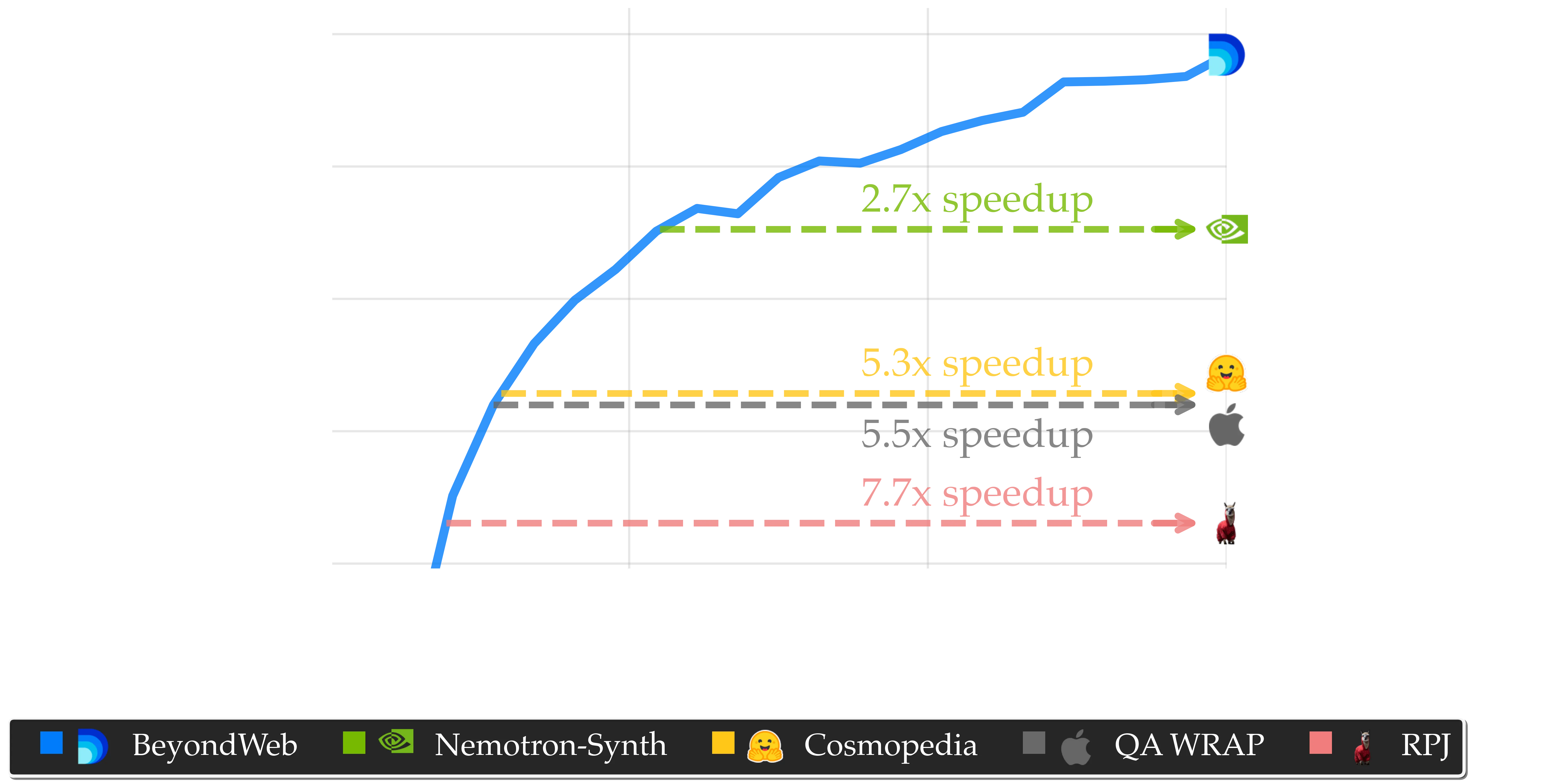
In 8B model scale, BeyondWeb achieve remarkable speedup up to 7.7× and 2.7× speedup (in time to reach baseline accuracy) over RedPajama and Nemotron-Synth respectively. The 8B models are trained for 180 billion tokens. Average Accuracy (%) is the mean across 14 benchmarks.
Establishing a new pareto frontier for synthetic data. Our results establish a new Pareto frontier for the speed-accuracy trade-off in language model pretraining, as visualized in Figure below. Remarkably, our 3B model (60.8% accuracy) outperforms all but the strongest of the 8B baseline models trained for the same number of tokens (180B), demonstrating that high-quality synthetic data can achieve superior results with dramatically fewer parameters. This highlights the scalability and headroom unlocked by high-quality synthetic data, enabling stronger models at lower computational cost and challenging the conventional reliance on ever-larger architectures.
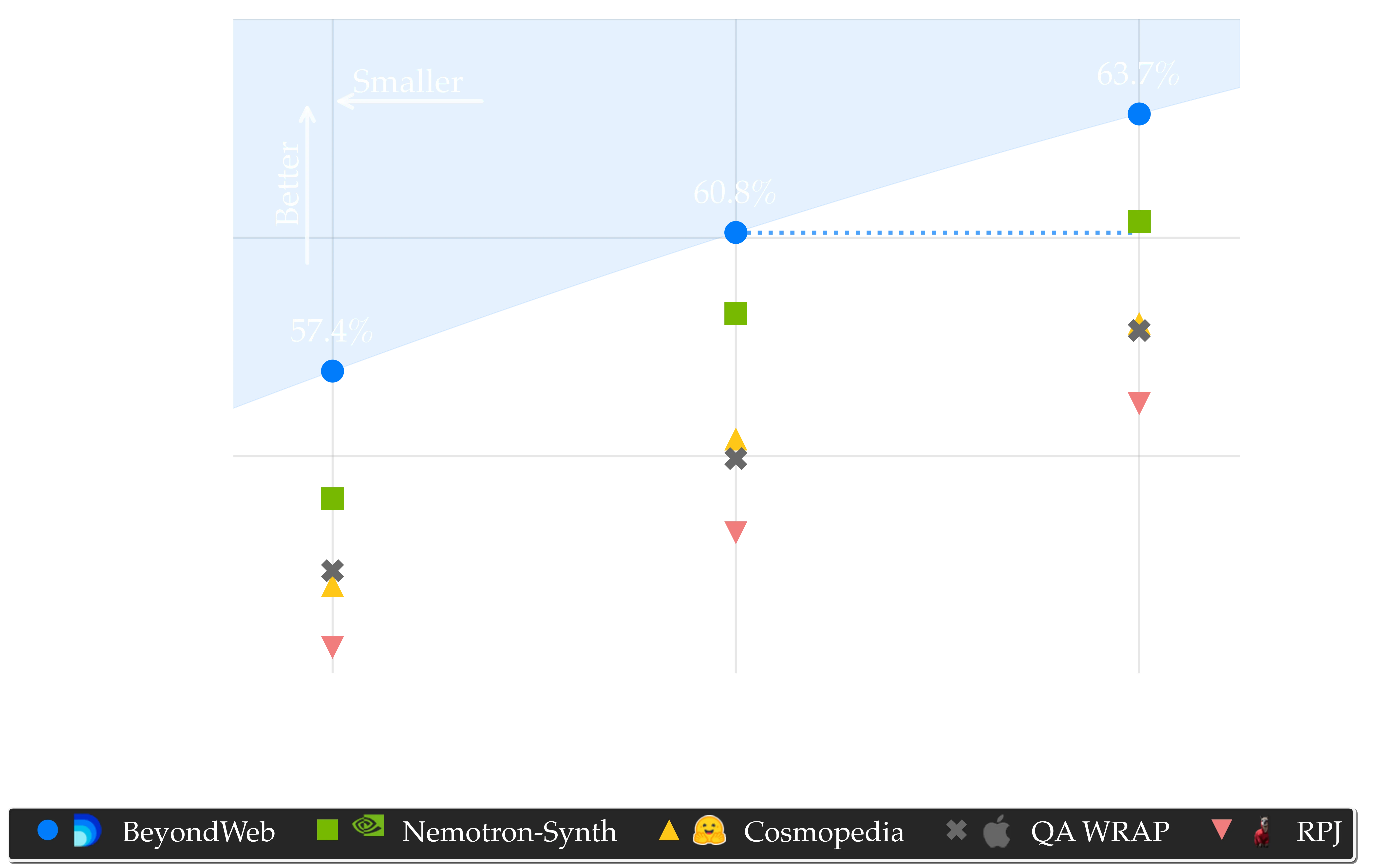
BeyondWeb establishes a new Pareto frontier for synthetic pretraining data. Notably, our 3B model outperforms all but one 8B model trained on baseline datasets with the same token budget. Average Accuracy (%) is the mean across 14 benchmarks.
Consistent improvements across tasks. As presented in the interactive plot below, BeyondWeb achieves the highest average accuracy at every model scale and also outperforms baselines on 13, 12, and 13 out of 14 tasks, in 1B, 3B, and 8B models, respectively. This demonstrates that the performance gains are not confined to a few standout benchmarks but are broadly distributed, reflecting the generalizability enabled by high-quality, diverse synthetic data.
Performance across all tasks in 0-shot, 5-shot, and averaged settings, for different model sizes.
We now examine the factors that contribute to the strength of synthetic data approaches such as BeyondWeb and the obstacles to generating high-quality synthetic pretraining data.
4. Systematically Evaluating Synthetic Data
4. Systematically Evaluating Synthetic Data
Despite the ready availability of web data for pretraining, training models solely on internet-sourced text presents several challenges. First, data redundancy is a major issue. Web data is finite, and modern pretraining budgets are beginning to exceed the scale of high-quality web data. Unfortunately, repeating data leads to diminishing returns and overfitting cite, and thus is not a substitute for new data. The second challenge is style mismatch, which describes the stylistic differences between the data models are trained on and the data they encounter at test time. The top three most common styles of web data are personal blogs, product pages, and news articles cite, whereas deployed models predominantly interact in conversational or instructional formats cite. The third challenge is that knowledge bottlenecks emerge in underrepresented domains, making models blind to certain topics. Finally, training efficiency can be significantly improved if data is structured to maximize per-token knowledge utility rather than merely increasing token count.
These challenges highlight the need to move beyond web data by generating synthetic data. However, not all synthetically generated data is equally effective. Through extensive experimentation and systematic ablations, we examine how synthetic data can help overcome data limitations, better align training distributions with inference-time requirements, and enhance both knowledge efficiency and diversity. Our systematic evaluation reveals several key findings, structured around three central themes: the capabilities of synthetic data, effective techniques for rephrasing, and the properties of generator models.
| Finding | Section |
|---|---|
What Does Synthetic Data Really Do? | |
| Are Generator-Driven Approaches Approximated by Summarization? Simple summarization approaches that increase per-token information density achieve similar performance as Cosmopedia. But carefully-crafted source rephrasing approaches can substantially outperform both. | §4.2 |
| Surpassing the Data Wall: Synthetic data generation must be thoughtful in order to breach the data wall. Naive strategies can not break the data wall. | §4.3 |
How to Rephrase: Methods & Techniques | |
| Quality Matters: Synthetically rephrasing high-quality web data offers larger performance gains than using low-quality web data. Nevertheless, high-quality input data alone is insufficient for generating the highest quality synthetic data. | §4.4 |
| Style Matters: Upsampling natural conversational data improves downstream task performance, though these improvements are modest and show diminishing returns with the proportion of conversational data. | §4.5 |
| Diversity Matters: As we scale synthetic data to 1T tokens, the importance of diversity in synthetic data generation is critical to avoid diminishing returns. | §4.6 |
Who Should Rephrase: Generator Properties | |
| Model Family Robustness: Synthetic data benefits are largely consistent across generator model families, and generator model quality is not predictive of synthetic data quality. Selecting a good rephrasing model may be straightforward as most work well, but selecting the best rephrasing model is not. | §4.7 |
| Generator Size Saturation: While larger generators help, improvements plateau beyond 3B parameters with diminishing returns beyond this scale. | §4.8 |
Summary of key findings organized by theme. Each finding represents a core insight from our systematic evaluation of synthetic data generation strategies.
4.1. Experiment Setup
4.1. Experiment Setup
As a baseline for the following sections, we use a subset of the RedPajama dataset cite. To construct high-quality splits from RedPajama, we follow the method from cite (HQ Web). Unless otherwise specified, all ablations train a Llama-3.2-1B model on a total budget of 20 billion tokens, with a 50:50 split between real (HQ Web) and synthetic data. Unless the experimental ablation demands otherwise, all synthetic data generation approaches rephrase the same 10 billion tokens of HQ Web data that are already a part of the final 20 billion data mixture. This means that the total source knowledge from the internet is fixed at 10 billion tokens. For a fair baseline that controls for the amount of new knowledge, RPJ-HQ baseline also sees the same 10 billion tokens, but twice during its training. For other curated datasets, such as Cosmopedia cite, we randomly sample 10 billion tokens from their corpus. All evaluations report the average performance across 0-shot and 5-shot settings on a benchmark suite of 14 tasks enumerated in Appendix B of paper.
4.2. RQ1: Are Generator-Driven Approaches Approximated by Summarization?
4.2. RQ1: Are Generator-Driven Approaches Approximated by Summarization?
One hypothesis that may explain the benefits of synthetic data is that it effectively increases the per-token information density of training data. Rather than merely generating more tokens, the efficacy derives from restructuring and distilling existing knowledge into more compact and informative representations. This hypothesis particularly prevails in the generator-driven paradigm, in which a large LLM is seeded with various topics of interest, and asked to create textbook-style material based on its parametric knowledge. Intuitively, when a model writes a book on a specific topic, say laws of motion, it distills all the information it has read about it on the internet into a much more condensed representation.
To test this hypothesis, we compare a generator-driven approach (Cosmopedia), with a simple rephrasing approach that merely attempts to increase the information density of the internet by summarizing it into more compact, high-quality content.
Summarize the following text. Directly start with the summary. Do not say anything else.
Experiment Design. We consider two approaches: (1) Cosmopedia, which prompts a large model to explain or teach concepts, reorganizing knowledge into compact, pedagogically optimized outputs. Cosmopedia uses an 8×7B model to generate high-quality data conditioned on seed topics. (2) Summarization, which compresses existing text using a prompt that aims to preserve essential information while reducing length. This approach leverages an 8B-parameter model with a simple prompt to summarize source content. Both approaches aim to condense learning-relevant content into fewer tokens, enabling more efficient training under fixed budgets. Following the setup in Section 4.2, we allocate 10 billion tokens for synthetic data and 10 billion tokens for the original dataset during training.
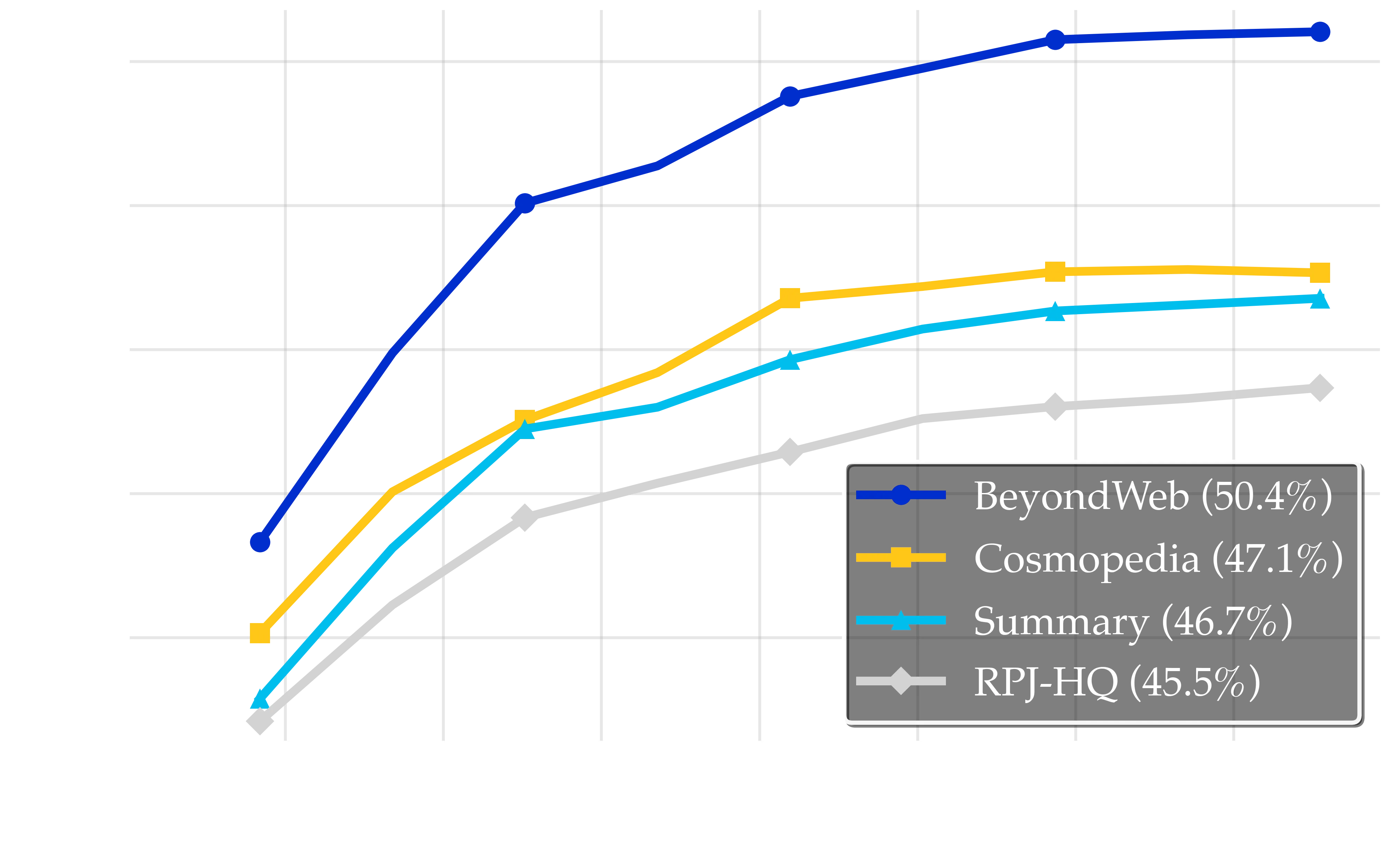
Knowledge transfer effectiveness across different synthetic data approaches. The yellow line represents Cosmopedia (46.8%), which uses a generator-driven, sophisticated educational content generation technique and 8×7B model; the cyan line denotes the Summary (46.8%) approach, which uses an 8B model and a simple summarization prompt; the gray line denotes the RPJ-HQ (no synthetic data) baseline. These results demonstrate that even naive summarization achieves substantial improvements similar to those of Cosmopedia, suggesting distillation works through increased information density rather than complex knowledge transfer.
Results and Observations
Our analysis reveals that even simple distillation strategies can achieve substantial performance improvements:
-
Simple summaries match generator-driven methods: The summarization approach (46.7%) nearly matches the performance of the more sophisticated and compute-intensive Cosmopedia approach (47.1%). This suggests that much of the benefit of synthetic data arises from basic information condensation. Notably, summarization, which uses a single 8B-parameter model along with information on the internet, nearly matches the performance of Cosmopedia, which relies on a much larger setup of 8×7B-parameter model and manually curated seed topics to guide generation. Importantly, this shows that in the case of Cosmopedia, much of the benefit of the generator-driven paradigm can be achieved using the source-rephrasing paradigm and a simple summarization prompt.
-
Increasing token information density improves model performance: The fact that naive summary prompts achieve a +1.2pp improvement over the baseline (45.5%) indicates that increasing per-token information density is one mechanism (among potentially many) by which synthetic data improves pre-training.
-
Synthetic data is not just knowledge distillation: While summarization shows similar benefits as Cosmopedia, BeyondWeb outperforms summarization-based approaches with 50.4% accuracy (+3.7pp). This highlights that substantial gains are possible beyond basic distillation and underscores the importance of careful synthetic data generation.
4.3. RQ2: Can Synthetic Data Break the Data Wall?
4.3. RQ2: Can Synthetic Data Break the Data Wall?
Can synthetic data effectively compensate for limited high-quality real-world data? This section explores whether there exists a fundamental limit to model performance that cannot be overcome through synthetic data. Our results reveal a surprising finding: the data wall is surpassable depending on the type of synthetic data.
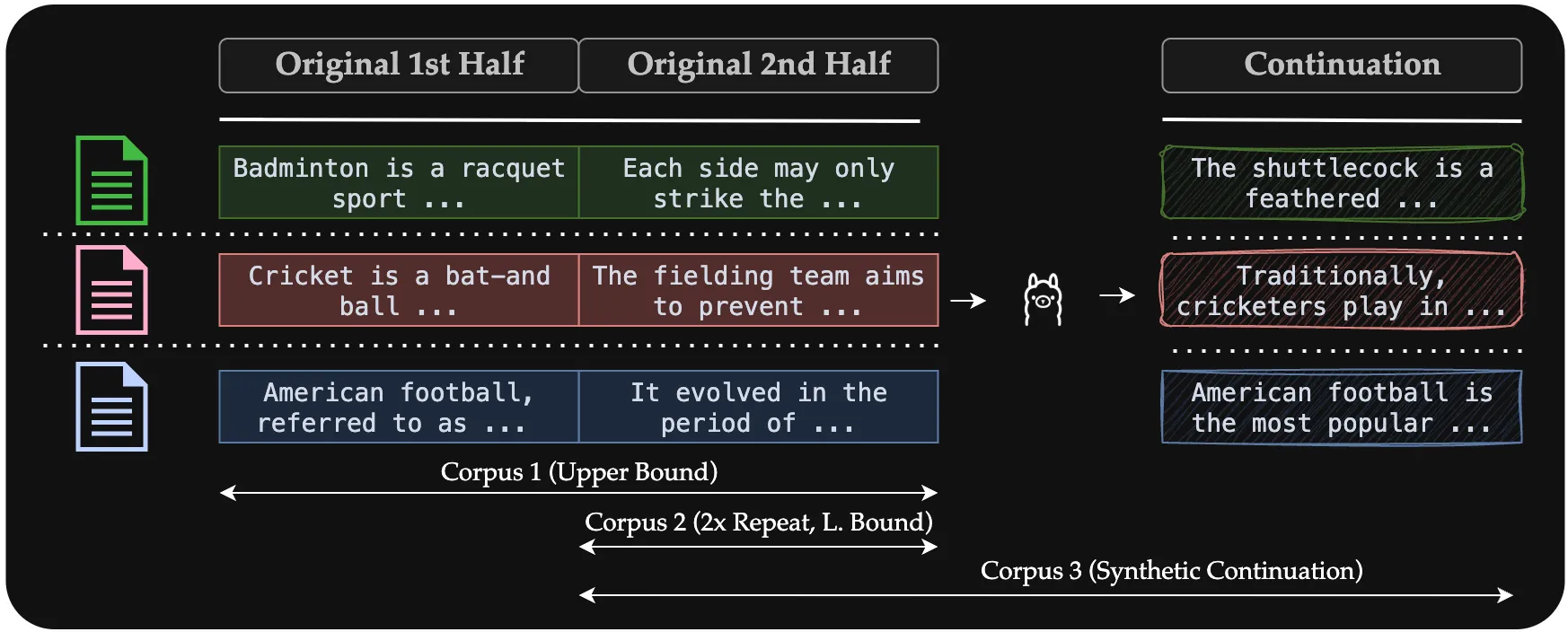
Illustration of data splitting and corpus construction strategies to enable a controlled setup. The figure shows how our 20 billion token dataset is divided and utilized across different experimental conditions. The top row displays three data segments: Original 1st Half (10B tokens of natural web content), Original 2nd Half (10B tokens of natural web content), and Continuation (10B tokens of synthetic content generated by extending documents from the first half). The example text snippets demonstrate how continuation generates stylistically consistent but novel content. The arrows below indicate corpus composition: Corpus 1 (Upper Bound) uses both original halves for full natural data coverage; Corpus 2 (2x Repeat) uses only the first half repeated twice; and Corpus 3 (Synthetic Extension) combines the second half with synthetic continuations. This experimental design isolates the effects of repetition versus synthetic augmentation when facing data constraints.
Continue the following text in the same style as the original.
Experiment Design. We designed three controlled datasets (see Figure above) to systematically compare different training approaches operating in a data-constrained setting of 20 billion tokens.
-
Full Data (Upper Bound). This represents our performance ceiling, utilizing the complete available dataset of 20 billion tokens without any repetition or synthetic augmentation. This corpus serves as the oracle baseline, representing the maximum achievable performance given our data constraint. The figure shows this as a complete, unbroken dataset.
-
2x Repeat (Lower Bound). This corpus simulates data scarcity by artificially constraining our dataset to only 10 billion unique tokens, then repeating this exact content twice to reach our full 20 billion token training budget. We split each paragraph at the sentence boundary closest to its midpoint, and only retain the second half of the paragraph. This approach represents a naive solution of repeating data to meet training token requirements, and serves as our lower bound.
-
Continuation (Naive Synthetic). Building on the same 10 billion token dataset as the previous strategy, this approach generates the remaining 10 billion tokens through simple model-driven continuation. An LLM (Llama-3.1-8B in this case) receives partial documents from the second half of the original dataset and is prompted to generate natural continuations. This represents the most straightforward approach to synthetic data generation, where models extend the available data. The synthetic content attempts to maintain stylistic consistency with the source material. We specifically chose the second half of each paragraph in the original data to avoid the confounding effect of the generator model already having seen the full sample during its own pretraining. If the generator model had seen the sample, then it may be able to ‘cheat’ by generating the true second half when prompted with the first half, and hence approximate the full data upperbound. This would allow us to test whether naive continuation of part of the data can approximate the whole.
Results and Observations.
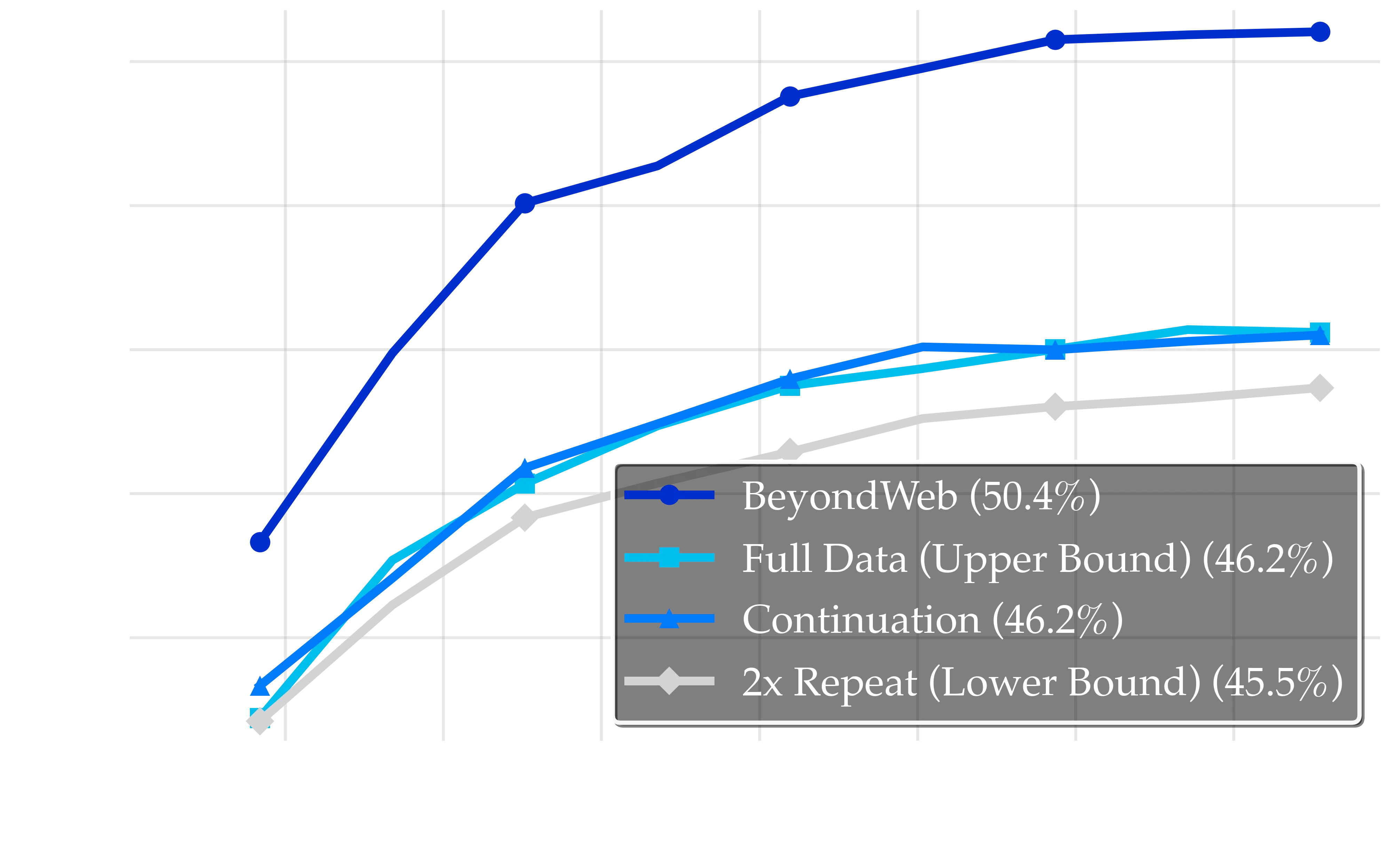
Performance comparisons across different data augmentation strategies during training. The dark blue line represents BeyondWeb (50.4%) which significantly surpasses all other approaches. The light blue line shows Continuation (46.2%), the cyan line depicts Full Data Upper Bound (46.2%), and the gray line represents 2x Repeat Lower Bound (45.5%). The striking visual separation emphasizes BeyondWeb’s +4.2pp improvement over the Full Data upper bound. This reflects how intentionality is critical to breaking the data wall with synthetic data, and not just any synthetic data will yield benefits.
Figure above offers a visual comparison of average accuracy across models pretrained on different datasets using various augmentation strategies.
-
Repetition leads to performance degradation: The 2x Repeat strategy (gray line) achieves only 45.5% accuracy, representing a 0.7pp drop from the full data baseline (46.2%). This demonstrates that naive data duplication leads to diminishing returns as seen in prior works cite.
-
Naive synthetic generation provides only modest improvements: The Continuation strategy (46.2%) offers a small +0.7pp gain over 2x Repeat (45.5%). This matches the Full Data upper bound, suggesting that simple model-generated extensions can potentially compensate for limited quantities of web data. We note that an important confounder in this experiment is that the continuation model has seen a lot more than the 20B tokens available for full data experiment. This means that it may be using its parametric knowledge to add ‘new knowledge’.
-
Strategic synthetic data breaches the data wall: BeyondWeb achieves 50.4% accuracy, surpassing the Full Data upper bound (46.2%) by +4.2pp. This finding demonstrates that carefully crafted synthetic data can exceed the performance ceiling of natural data. The data wall is not unsurpassable; it can be broken through strategic synthetic data generation.
4.4. RQ3: How Important is the Quality of the Seed Data for Rephrasing?
4.4. RQ3: How Important is the Quality of the Seed Data for Rephrasing?
An important design decision in synthetic data generation involves the quality of both the source material and the generated synthetic content. This raises a fundamental question: if one has limited high-quality data, is it better to use high-quality (but repeated) input data to seed synthetic rephrasing, or leverage lower-quality sources and turn them into high quality?
Experiment Design. We operate under a constraint of 10B tokens of high-quality data, along with an abundant supply of low-quality data. Following the method from cite, we sample a small subset of high-quality (HQ Web) data from RedPajama. We also use a random sample of the RPJ dataset as our low-quality subset (LQ Web). We then rephrase the LQ Web data to yield LQ Synth and the HQ Web data to yield HQ Synth, and compare training scenarios that use different quality combinations of synthetic and/or web data. We note that we rephrase the same HQ web data that we also use in the data mix.
Results and Observations.
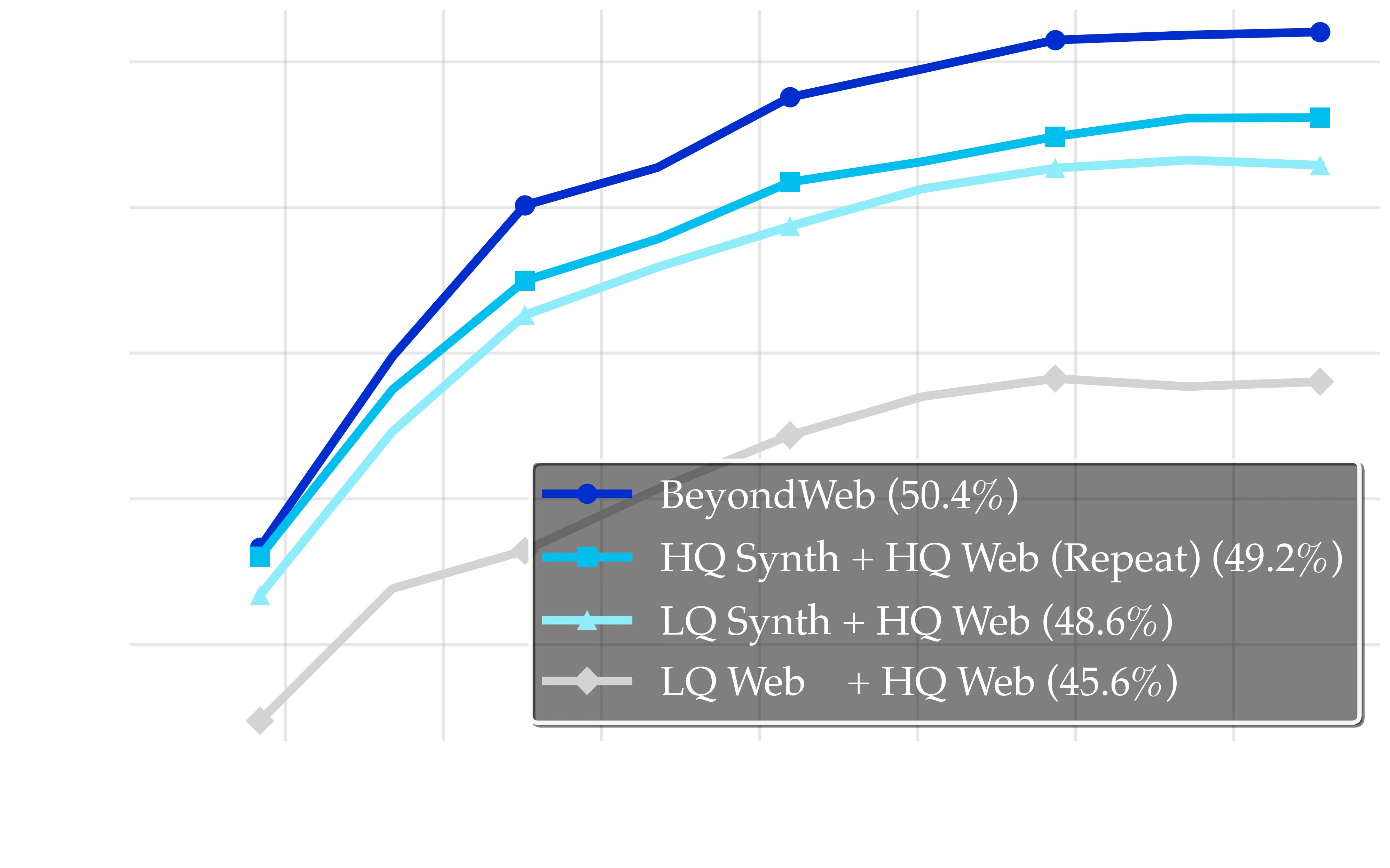
Performance comparison across different quality combinations in training data. HQ refers to high-quality web data, LQ refers to low-quality web data. The dark blue line shows BeyondWeb (50.4%), dark cyan shows HQ Synth + HQ Web (49.2%), where the synthetic data are rephrased versions of the HQ web samples, and the light cyan line shows LQ Synth + HQ Web (48.6%). The gray baseline corresponds to LQ Web + HQ Web (45.6%). These results indicate that improving the quality of input data for rephrasing improves the rephrased data, even when there is overlap with the original input data. But improved input data quality alone is inadequate for producing the highest quality synthetic data.
Figure above shows two important insights about input data for rephrasing:
-
High-Quality Seed Data Dominates: The high performance of the combination of HQ Synth + HQ Web (49.2%) demonstrates that starting with high-quality source material for synthetic rephrasing is crucial. Notably, the BeyondWeb performance at 50.4% shows that there remain other avenues for performance improvement beyond high-quality source data.
-
Quality Trumps Novelty: The LQ Synth + HQ Web combination (48.6%) underperforms the HQ Synth + HQ Web data (49.2%), indicating that the quality of seed data for synthetic generation matters more than ensuring complete novelty in the knowledge base. However, it still provides a +3.0pp improvement over the baseline.
4.5. RQ4: Is Distributional Style Matching Important?
4.5. RQ4: Is Distributional Style Matching Important?
While vast amounts of text data are available online, the natural distribution of web content is different from the types of text typically encountered at inference. For instance, the internet is dominated by personal blogs, news articles, and product pages cite. However, evaluation use cases typically involve chat, or in-context learning abilities. These can together be stylistically seen as a ‘ping-pong’ rally between questions and answers, or users and assistants. We investigate the impact of this implicit distribution shift between train and test, and if such stylistic alignment can be one mechanism by which synthetic rephrasing can improve model performance.
Estimating the amount of conversational web data.
We first estimate the fraction of conversational data in the general web corpus. To do so, we sampled 10k random examples from the RedPajama dataset, and queried the gpt4o model to label them as conversational or not. Here conversational refers to various forms of texts which have a ‘ping-pong’ effect (see Appendix in paper for prompt). Our analysis indicated that conversational dialogue comprises less than 2.7% of internet text. Yet, the dominant use case for modern language models lies in chat-based applications, such as virtual assistants, customer service bots, and interactive tools.
This discrepancy reveals a gap between the training distribution and real-world model usage. The formats and interaction styles most relevant to deployment, such as multi-turn dialogue, question answering, and instructional content, are significantly underrepresented in naturally occurring data. Synthetic rephrasing provides a mechanism to bridge this gap by generating examples in the specific forms and contexts that matter for downstream applications.
Estimating the impact of conversational web data.
To systematically evaluate the impact of style alignment, we conduct controlled experiments that vary the proportion of conversational content in our training data while maintaining constant token budgets and data quality. We leverage the style classification filters from Organize the Web cite to identify naturally occurring conversational content within the RedPajama dataset. From their 20 identified web content styles, we focus on four that exhibit conversational characteristics: Audio Transcript, Customer Support, FAQ, and Q&A Forum. Manual inspection confirmed these categories contain the back-and-forth dialogue patterns characteristic of conversational interaction.
As a validation of our previous investigation, this naturally occurring conversational content comprises 3.67% of the RedPajama dataset, closely aligning with our independent GPT-based estimate of 2.7% mentioned earlier. We construct three training datasets with varying conversational ratios: 10%, 20%, and 50% conversational content, with the remainder consisting of randomly sampled RedPajama data. Each dataset maintains our standard 20 billion token training budget, enabling direct performance comparisons across different style distributions.
Results and Observations.
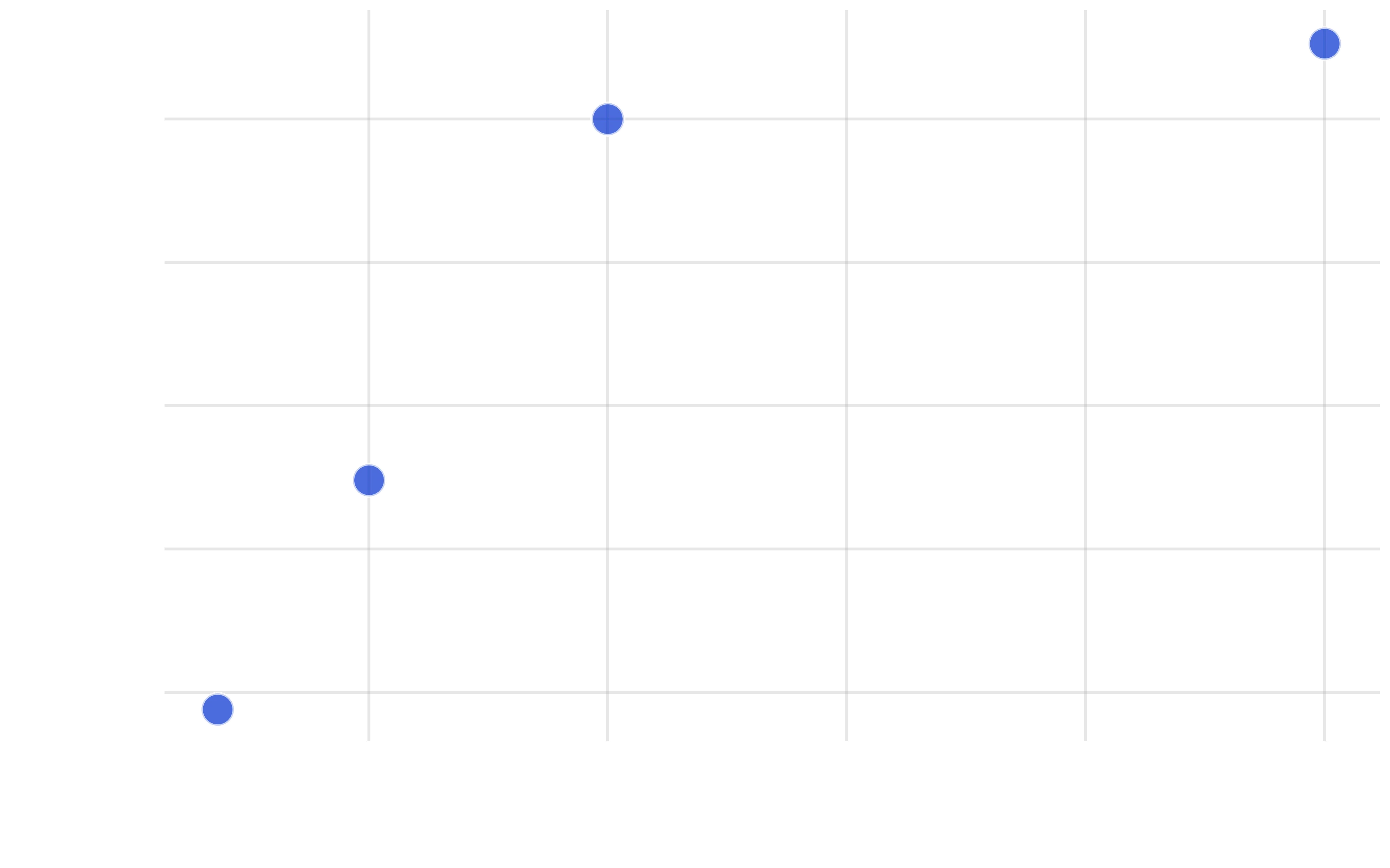
Effect of conversational data ratio on final accuracy. The first point corresponds to the RPJ baseline (randomly sampled) which contains 3.67% conversational data. For each of the other points, we upsampled conversational data in RPJ to the desired ratio and replaced the remaining portion with randomly sampled RPJ data to achieve the 20B token training budget. Increasing the percentage of conversational data beyond the 3.67% baseline can improve performance by up to 0.9pp at 50% conversational data, but the gains saturate beyond 20%, indicating that style-matching is important, but not sufficient for maximizing synthetic data quality.
Since our focus is on multi-turn, back-and-forth conversations, for this evaluation we measure only the 5-shot performance of the trained models. We find that increasing the proportion of conversational content in pretraining improves model performance (Figure above). The first point represents the RPJ baseline, which contains 3.67% conversational data from random sampling. For higher ratios, we upsample conversational data within RPJ to the target percentage and replace the remaining portion with randomly sampled RPJ data. Performance increases from 43.2% at the baseline to 44.1% at 50% conversational content, with 10% and 20% conversational data yielding 43.5% and 44.0%, respectively. This trend confirms that increased exposure to conversational patterns during pretraining modestly enhances downstream task capabilities, though gains exhibit diminishing returns.
4.6. RQ5: How Important is Diversity at Scale?
4.6. RQ5: How Important is Diversity at Scale?
In the previous section, we found that aligning styles between train and test time has positive but diminishing gains. This finding highlights a critical limitation: while style alignment helps initially, models eventually saturate on uniform synthetic data patterns. This leads us to examine the importance of diversity in synthetic data generation.
We investigate a fundamental question: How does synthetic data diversity affect model performance when scaling to trillions of tokens? Specifically, do diverse generation strategies maintain benefits throughout extended training, or do all approaches eventually plateau?
Our experiments reveal that different synthetic data generation approaches yield dramatically different scaling outcomes, with approaches that emphasize diversity, exemplified by BeyondWeb, significantly outperforming fixed synthetic data generation techniques.
Experiment Design.
To understand the scaling effects of different synthetic data strategies, we analyze training dynamics across model scales through extended training runs. Among the strategies we investigate, Cosmopedia generates a textbook related to a web sample under the generator-driven paradigm, QA Wrap rephrases existing web documents into conversational question-answers. Nemotron-Synth builds on top of WRAP by diversifying the prompts beyond just conversational question-answering, into various styles like MCQ, Yes/No questions, open-ended questions, reading comprehension tasks, logical problem solving tasks, and so on. BeyondWeb further prioritizes diversity in synthetic data generation, and prioritizes learning patterns that aid learning and information retention.
Results and Observations.
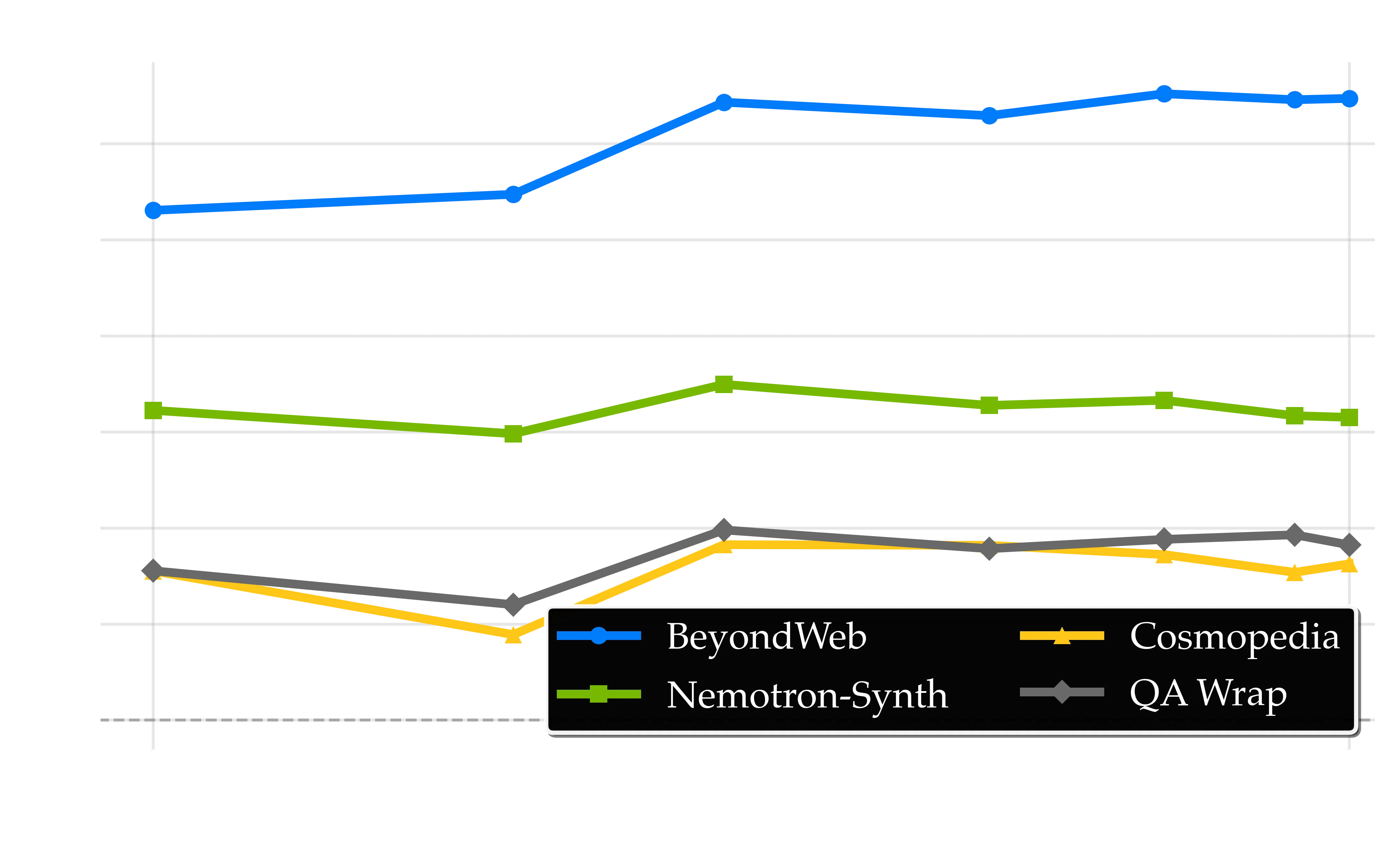
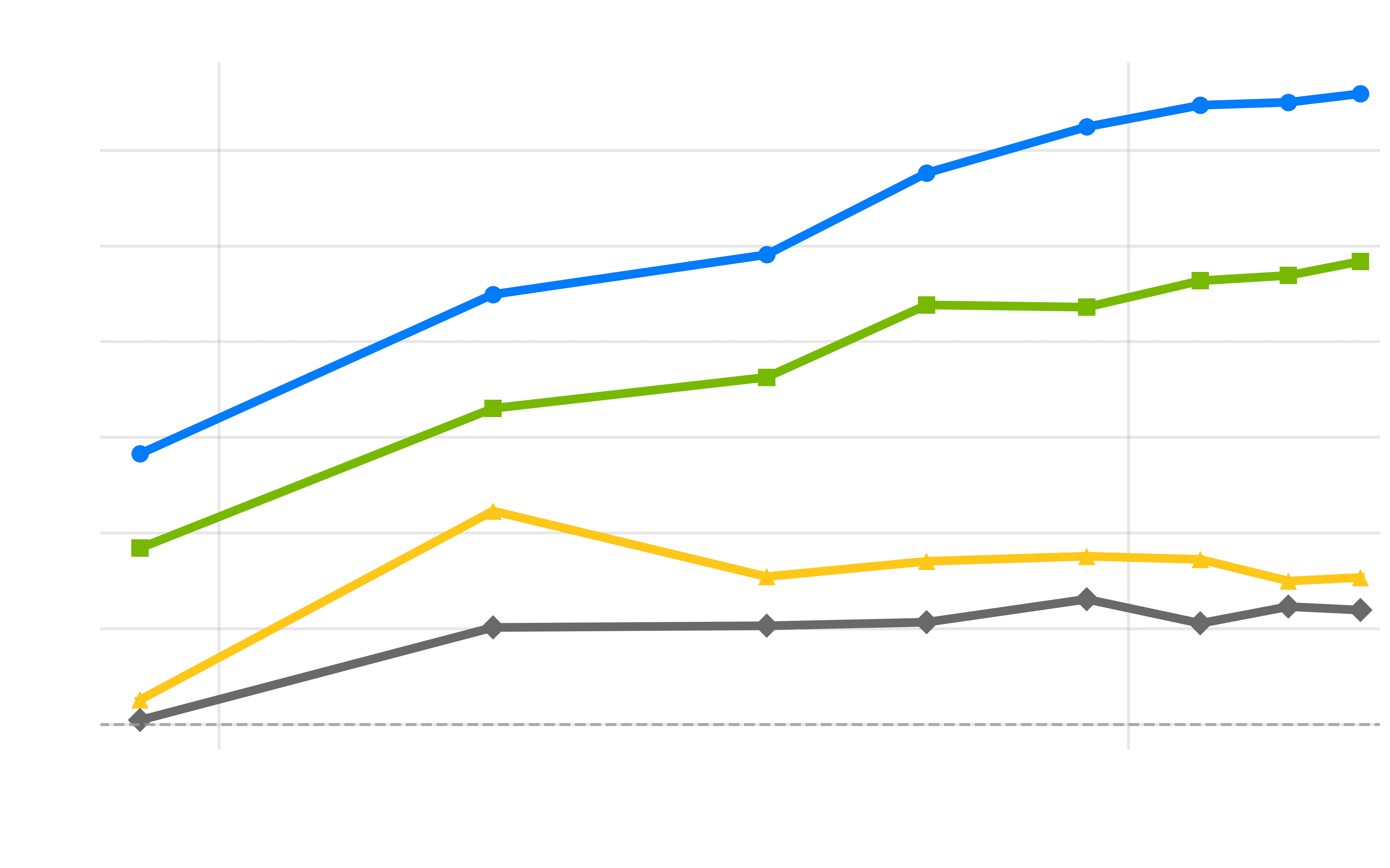
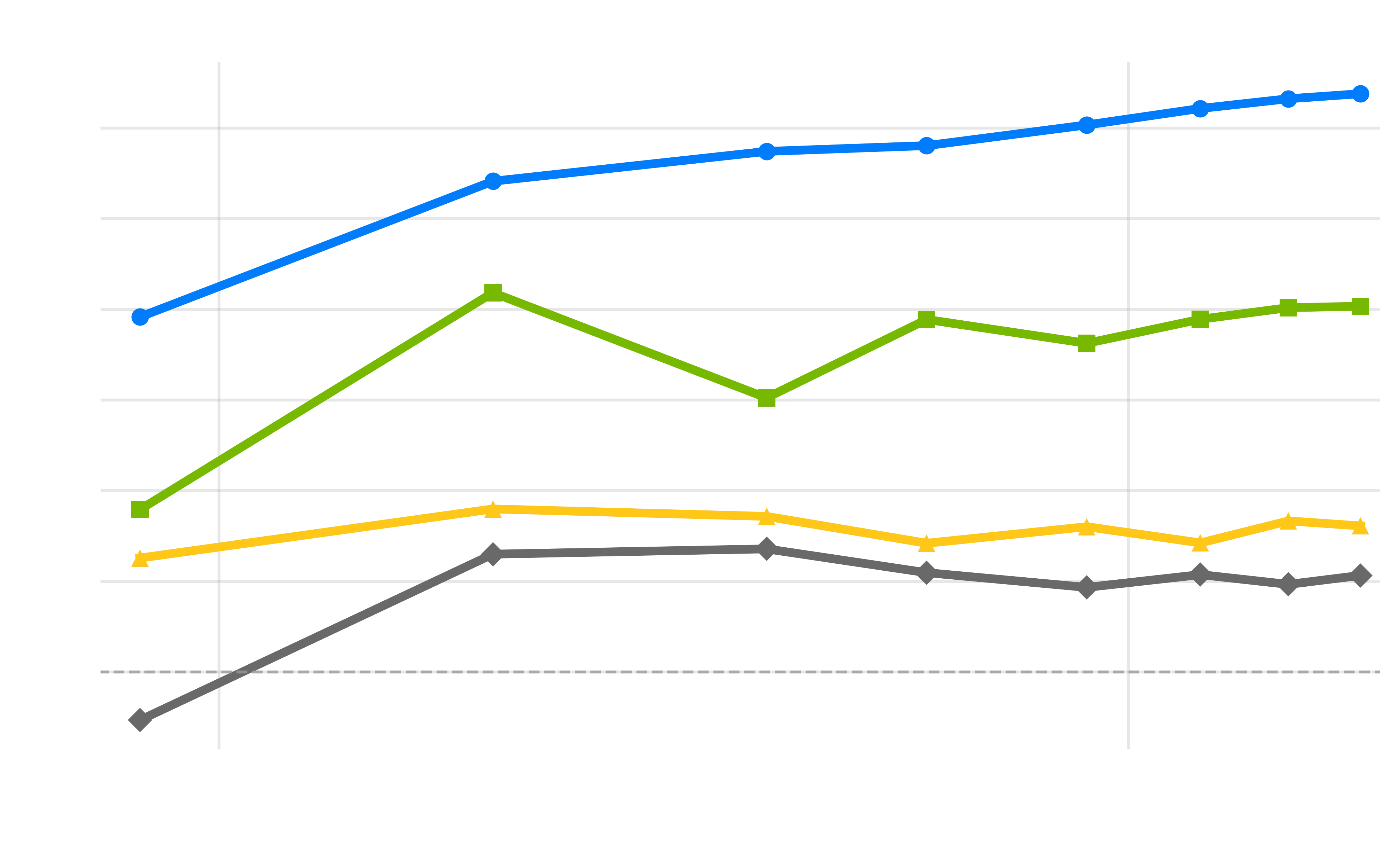
Training dynamics across model scales showing performance improvements relative to RedPajama baseline. Left: 1B Scale, Center: 3B Scale, Right: 8B Scale. BeyondWeb (blue) maintains consistent positive slopes across all scales, while QA approaches (cyan) show early gains followed by plateauing effects, particularly evident in larger models. Notably, at 1B scale, models are trained to saturation at approximately 50× beyond Chinchilla optimal compute. Where other baselines begin to overfit and degrade, BeyondWeb continues to grow in its improvements over RedPajama performance. The sustainable improvement curves demonstrate that diverse generation strategies provide more robust long-term benefits than single-strategy approaches across training regimes. Note that in order to smooth intermediate fluctuations, each data point on the plot is the average accuracy of multiple previous intermediate checkpoints (e.g. the 100B token checkpoint is the average of all checkpoints until 100B, the 200B checkpoint is the average of all checkpoints between 100B and 200B, etc).
The training dynamics reveal fundamental differences between generation strategies as we scale to hundreds of billions of tokens of data, particularly evident across different training regimes. Diversity in synthetic data generation manifests in two critical ways:
-
Diversity provides an initial performance bump: Multi-strategy approaches like BeyondWeb provide substantial early gains as models quickly benefit from immediate exposure to diverse formats and styles. We hypothesize this aids learning by making patterns that align with model’s final usage, core to its early representations.
-
Diversity leads to sustained improvements: Diverse generation strategies continue providing learning benefits throughout extended training, even in overtrained regimes. At the 8B scale, the marginal improvements for BeyondWeb over RPJ (y-axis) continue to increase, whereas the benefits for strategies such as Cosmopedia (which generates a fixed style of textbook content) tend to saturate. Remarkably, at 1B scale where models are trained approximately 50× beyond Chinchilla optimal compute, BeyondWeb maintains positive performance trends while other baselines begin to overfit and show degraded performance, demonstrating the robustness of diverse synthetic data against overfitting in extreme training regimes.
4.7. RQ6: How Important is the Synthetic Rephraser Model Family?
4.7. RQ6: How Important is the Synthetic Rephraser Model Family?
A key difference between the source rephrasing and the generator-driven approach is that the synthetic data generator is not required to be the ‘source’ of the knowledge. Instead it only needs to transform the data to make it more useful for pretraining. While existing work like Cosmopedia cite and Phi-1.5 cite required large generator models, Mixtral-8×7B-Instruct-v0.1 cite and GPT-4, respectively, we question whether the specific generator family used for rephrasing significantly impacts the quality of the rephrased data.
Experiment Design.
We test the importance of generator family by using 4 different generator models: (i) OLMo-2-7B cite, (ii) Phi-4-14B cite, (iii) Mistral-7B-v0.3 cite, and (iv) Llama-3.1-8B cite. We use the same rephrasing prompt for each model and evaluate the performance of a model trained on the synthetic data generated by each of these generator models. We generated 10B tokens of synthetic data using each of them, combined it with 10B tokens of web data, and trained a model on each of the resulting 20B token datasets.
Results and Observations.
Synthetic data rephrased using different model families consistently produces high-quality training data, with the resulting datasets achieving gains ranging from +3.4pp to +4.4pp over the RPJ baseline (45.5%). All model families were within ±1pp of each other, with OLMo-2-7B achieving the highest performance (49.9%) and Mistral-7B-v0.3 the lowest (48.9%).
We compare the general benchmark performance of each rephraser model (OLMo-2-7B: 59.6%, Llama-3.1-8B: 61.2%, Mistral-7B-v0.3: 66.0%, and Phi-4: 66.6%) with the quality of the synthetic data they produce, measured by the performance of models trained on their rephrased outputs. While the rephrasers span a 7-point range in general accuracy, the quality of the resulting synthetic datasets is strikingly similar, differing by less than 1 percentage point across generators. Notably, OLMo-2-7B, despite having the lowest benchmark accuracy, produces the highest-quality synthetic data in our evaluation (49.9%). This lack of positive correlation indicates that a model’s general language modeling ability does not determine synthetic data quality, highlighting that even comparatively weaker models can be highly effective rephrasers.
These findings suggest that the primary driver of performance is not the generator’s general language modeling capabilities, but rather the limited and simpler capability to perform effective rephrasing and data transformation, which appears to be consistent across different model families. This generator-agnostic behavior means that organizations can deploy synthetic data pipelines using available model families without worrying about generator-specific optimizations, thereby reducing overall resource usage and enabling the viability of open-source and permissible models.
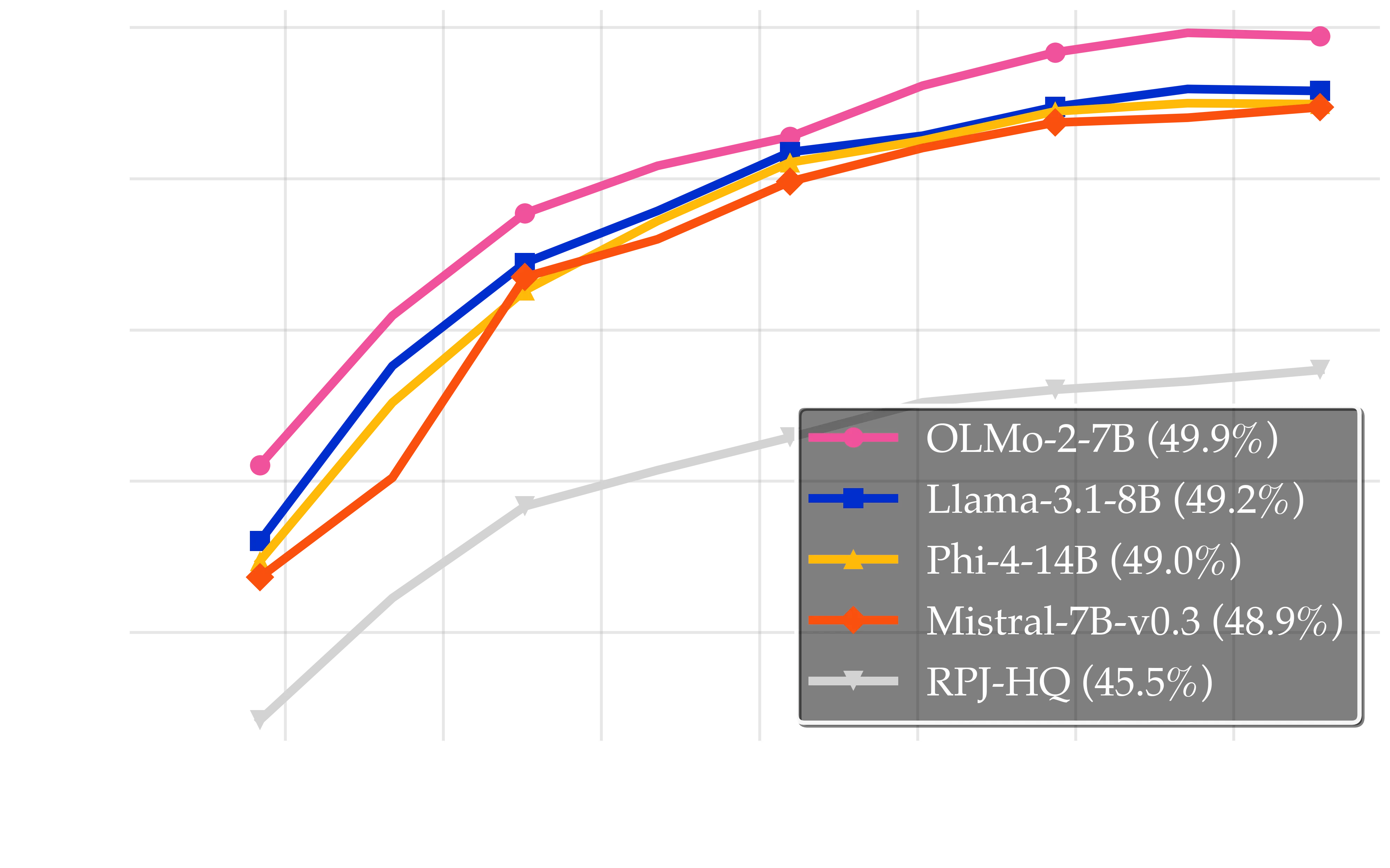
Synthetic data benefits are largely consistent across generator model families, and generator model quality does not predict synthetic data quality. Left: This plot shows the quality of models trained on synthetic data generated by different models: the pink line represents data generated by OLMo-2-7B (49.9%), the yellow line shows data generated by Phi-4-14B (49.5%), the orange line indicates data generated by Mistral-7B-v0.3 (48.9%), and the blue line depicts data generated by Llama-3.1-8B (49.2%). Models trained on each of these synthetic datasets achieve substantial improvements over the gray baseline representing RPJ (45.5%), with three out of the four models generating synthetic data of nearly identical quality, and OLMo-2-7B generating better data. Right: We plot the benchmark performance (on the x-axis) of the rephraser models used for synthetic data generation and contrast with the performance of the LLM trained on their generated data (marked as synthetic data quality on the y-axis). We observe that the benchmark performance of a language model does not positively correlate with its rephrasing capability.
4.8. RQ7: Does Rephraser Size Matter?
4.8. RQ7: Does Rephraser Size Matter?
Having observed near-invariance in the performance of synthetic data generated by different model families, we now turn to the question of whether the size of the rephraser model affects synthetic data quality. Rephrasing is a much more constrained task than open-ended generation, so it’s possible that even small models may be able to generate high-quality synthetic data via rephrasing. This is once again in contrast to the generator-driven paradigm where the generator model is required to be the ‘source’ of the knowledge, and the quality of the synthetic data is heavily dependent on the size of the generator model cite.
Experiment Design. To investigate this, we used Llama-3 models of varying sizes, 1B, 3B, and 8B, to generate 10B tokens of synthetic data. We combined the 10B synthetic tokens with 10B tokens of web data, and trained a model on each of the resulting 20B token datasets.
Results and Observations.
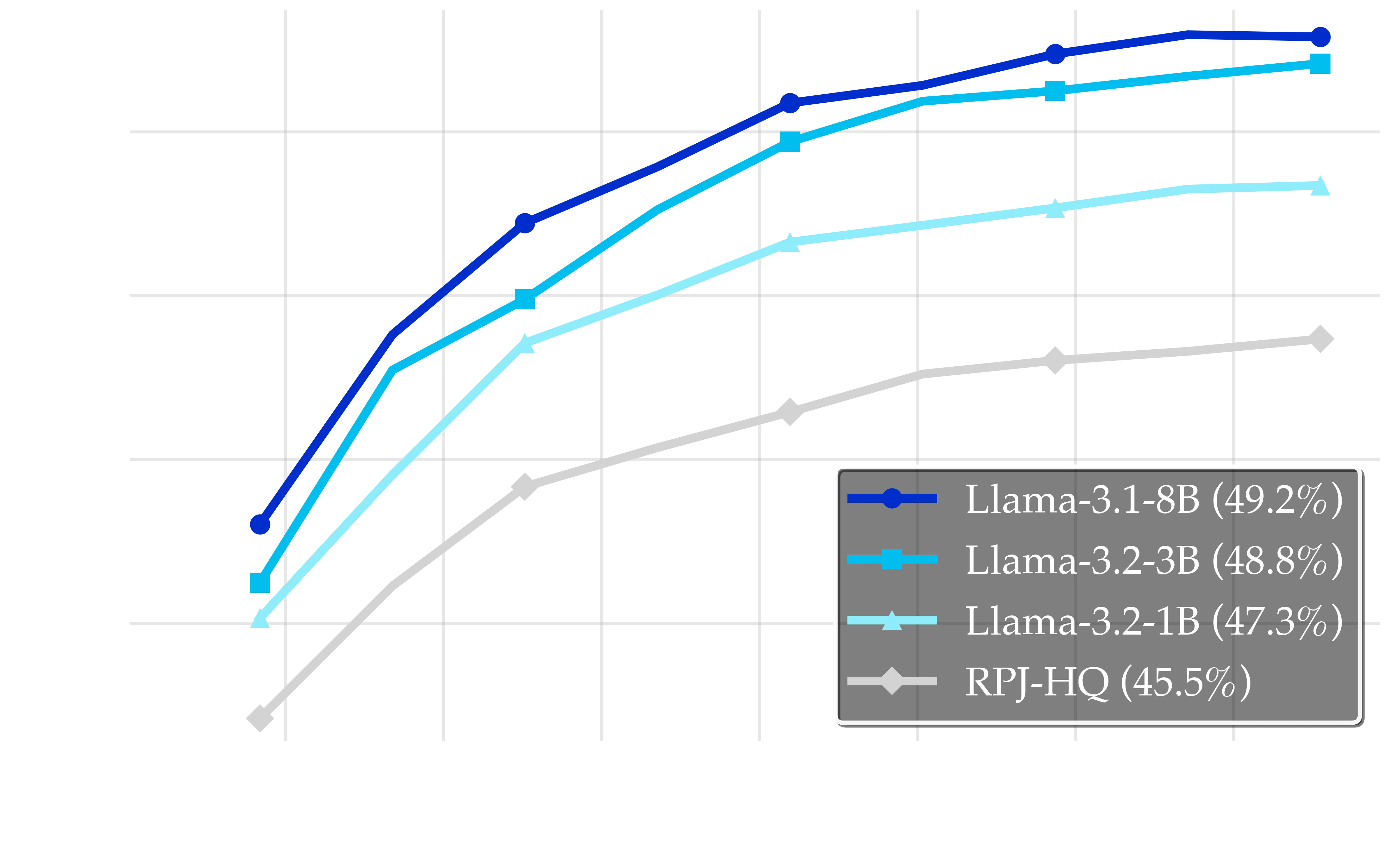
Effect of generator model size on synthetic data quality. The plot demonstrates the impact of generator size: the light cyan line shows Llama-3.2-1B generator performance (47.3%), the cyan line represents Llama-3.2-3B generator results (48.8%), and the dark blue line indicates Llama-3.1-8B generator performance (49.2%). The improvement from 1B to 3B (+1.5pp) is substantial, while the gain from 3B to 8B (+0.4pp) shows diminishing returns. The gray baseline at 45.5% represents RPJ performance, emphasizing the consistent improvements achieved by all generator sizes.
As depicted in Figure above, larger generators consistently produce better synthetic data, yielding substantial downstream performance gains (+3.7pp for 8B, +3.3pp for 3B) over RPJ baseline (45.5%). The 1B generator also shows significant benefit (+1.8pp), demonstrating that small generators can be effective. Larger LLMs provide only small additive gains.
While the 8B model (49.2%) slightly outperforms the 3B model (48.8%), the small gain (+0.4pp) indicates diminishing returns beyond 3B. This near-saturation makes small models a cost-efficient and practical choice for many applications, offering a strong balance between quality, speed, and compute overhead.
Larger generators likely offer advantages in knowledge depth, reasoning, and content diversity, which smaller models cannot replicate. However, this 3B capability threshold makes high-quality synthetic data accessible to researchers with limited computational resources.
5. Future Directions
5. Future Directions
Our work with synthetic data opens several research directions that warrant further investigation:
Scaling Laws and Inherent Repetition. A crucial area for future research lies in understanding the scaling laws specific to synthetic data. Unlike real data, where repetition is explicit and measurable, synthetic data presents a more nuanced form of inherent repetition stemming from the generating model’s architecture and the prompting methods used. This intrinsic repetition, governed by the model’s parameters and rephrasing strategies, requires new theoretical frameworks and metrics for quantification. The development of such metrics would enable us to better assess the true value and diversity of synthetic data. This understanding is particularly important as we scale up synthetic data generation, as it could reveal fundamental limits or opportunities that differ from those observed in traditional scaling laws for real data.
Democratizing Synthetic Data Generation. An important observation from our work is that the task of rephrasing, at its core, doesn’t necessarily require extensive world knowledge. This suggests the possibility of using much smaller models for synthetic data generation, which could significantly reduce computational costs. Future work should explore the minimal model size required for effective rephrasing while maintaining quality, potentially making synthetic data generation more accessible to researchers with limited computational resources.
Alignment with Human Values. Since the synthetic data generation process offers greater control, it creates promising opportunities for developing pretraining methodologies that explicitly promote alignment with human values cite. This aspect of synthetic data training could provide a powerful tool for addressing alignment challenges in language model development, offering an alternative to post-hoc alignment techniques cite.
Applicability Across Data Domains. While the present work, like most documented applications of source rephrasing, uses web data as input, the approach is not inherently limited to web data or even the text modality. It can be applied to domain-specific or proprietary data without requiring the rephrasing model to possess domain expertise, making it broadly suitable across diverse settings. Future work should explore applying such techniques to new domains and modalities, using synthetic data generation to help overcome the inherent data wall.
These research directions highlight the potential of synthetic data to not only improve model performance but also to address fundamental challenges in machine learning, from accessibility and scalability to alignment and safety. Future work in these areas could significantly impact how we approach language model training and deployment.
6. Conclusion
6. Conclusion
Pretraining now routinely encounters a data wall: the supply of high-quality, information-dense web text can not keep up with modern training budgets. Synthetic data has emerged as a natural and effective response, yet the scientific understanding of when and how it helps has remained limited. We address this by studying synthetic data for pretraining at scale and introduce BeyondWeb, a rephrasing-driven approach grounded in real web documents and diversified across styles and formats.
Our work identifies three general principles for effective synthetic data generation: prioritize quality over novelty by rephrasing high-quality sources rather than adding low-quality content; align the training data style with the deployment use-case; and maintain diversity in generation to sustain improvement over long training horizons. We show that these benefits are robust across generator families and saturate beyond moderate rephraser sizes, indicating that effective synthetic data generation does not require a particular model architecture or very large generators. However, we also show that the contribution of each of these factors in isolation is often modest, and no single factor is sufficient to yield high-quality synthetic data.
Taken together, these results demonstrate that high quality synthetic pretraining data is challenging to generate, even more challenging to ensure the efficacy of for larger models and training budgets, and risks being extremely costly to generate. Furthermore, there is no silver bullet for synthetic data, strong outcomes require jointly optimizing many variables. However, all of these challenges and risks are surmountable with thoughtful, scientifically rigorous source rephrasing, as evidenced by BeyondWeb substantially outperforming other public synthetic pretraining data offerings.
Get in Touch!
Get in Touch!
If you’re interested in pushing the bounds of what’s possible with data curation, we’re looking for talented Members of Technical Staff who have experience doing data research, building research tooling, translating science into products, and building scalable data products.
If you’re interested in training multimodal and/or text models faster, better, or smaller, Get in touch!
Follow us on twitter for insights (and memes) about data!
Contributions and Acknowledgements
Contributions and Acknowledgements
Core Research
Pratyush Maini and Vineeth Dorna.
steering the ship, wrangling the data, and keeping the Celsius industry thriving.
Core Infrastructure
Parth Doshi, Aldo Carranza, Fan Pan, Jack Urbanek and Paul Burstein.
the all-star cast who turned Mazra into code, numbers, and wins.
Leadership
Bogdan Gaza, Ari Morcos, and Matthew Leavitt.
the wise captains that made sure we didn’t steer into a bad baseline.
Contributors
Alex Fang, Alvin Deng, Amro Abbas, Brett Larsen, Cody Blakeney, Charvi Bannur, Christina Baek, Darren Teh, David Schwab, Haakon Mongstad, Haoli Yin, Josh Wills, Kaleigh Mentzer, Luke Merrick, Ricardo Monti, Rishabh Adiga, Siddharth Joshi, Spandan Das, and Zhengping Wang.
the ping-pong maestros who kept latency low and rallies long.
Acknowledgements
Gem De Leon and Kristin Reinke for fueling us with Beyond Burgers and unshakable good vibes. Jacqueline Liu and Tiffanie Pham for assembling the all-star cast that made this work possible.
Liz Gatapia for the beautiful logo design.
Kylie Clement, Jeremy Custenborder and Elise Clark for their sharp-eyed feedback on the draft.
the backstage crew who kept us fed, staffed, and focused.